"일지도"의 두 판 사이의 차이
cdc wiki
(→개발과제의 기대효과) |
(→향후계획) |
||
| (같은 사용자의 중간 판 16개는 보이지 않습니다) | |||
| 86번째 줄: | 86번째 줄: | ||
===기술개발 일정 및 추진체계=== | ===기술개발 일정 및 추진체계=== | ||
====개발 일정==== | ====개발 일정==== | ||
| − | + | :[[파일:일지도 개발 일정.png]] | |
| + | |||
====구성원 및 추진체계==== | ====구성원 및 추진체계==== | ||
| − | + | :이상엽: 기획, 예산 관리, 사무 등 | |
| + | :허가경: 데이터베이스 구축 및 API 가공/저장 | ||
| + | :게를 사이칸 무릉: OCR 기능 구현 및 연동 | ||
| + | :손도수렝: CSS/그래픽 인터페이스 구현, React/파이썬 연동 구현 | ||
==설계== | ==설계== | ||
===설계사양=== | ===설계사양=== | ||
| − | ==== | + | ====사용자 요구사항==== |
| − | + | :데이터 검색: 한 메뉴가 어떤 재료로 만들어졌는지, 혹은 특정 재료가 들어간 음식에는 무엇이 있는지 등에 대해 검색한다. | |
| − | + | :데이터 추가/수정/삭제: 서비스의 데이터베이스에 존재하지 않는 메뉴에 대한 정보를 추가, 혹은 기존 데이터에 대한 정보를 수정/삭제한다. | |
| − | + | :사진 인식: 모르는 언어로 된 메뉴판 등을 사진으로 찍어 번역한다. | |
| + | :회원가입을 통한 서비스의 개인화: 회원가입 후 검색 조건을 저장해 개인화된 서비스를 이용한다. | ||
| + | :회원탈퇴: 회원탈퇴를 통해 저장된 개인 정보를 삭제한다. | ||
| + | :비회원 사용: 회원가입 없이 서비스만 이용할 수 있다. | ||
| − | === | + | ====사용자 요구사항 만족을 위한 기능 정의==== |
| − | + | :데이터 검색: 알레르기 유발/기호/종교/신념 등 다양한 조건을 설정한다. 그 다음 메뉴명을 검색해 구성 재료를 알아볼 수 있고, 재료명을 검색해 해당 재료가 들어간 메뉴를 알아볼 수 있다. | |
| + | :데이터 추가/수정/삭제: 관리자 혹은 사용자가 데이터를 직접 추가/수정/삭제할 수 있다. | ||
| + | :사진 인식: OCR을 이용해 사진에서 문자/숫자를 인식해 텍스트로 추출하여 검색에 이용할 수 있다. | ||
| + | :회원가입을 통한 서비스의 개인화: ID/PW/이메일 등의 정보를 이용해 회원가입하고, 검색 시 설정한 조건을 해당 계정에 저장할 수 있다. | ||
| + | :회원탈퇴: 회원탈퇴를 하여 저장된 개인 정보를 삭제할 수 있다. | ||
| + | :비회원 사용: 비회원도 검색 조건 저장을 제외한 서비스를 이용할 수 있다. | ||
| + | |||
| + | ====기능 구현을 위한 세부기술 선택사항(디자인)==== | ||
| + | :Tesseract: OCR(광학 문자 인식) 기능을 제공하는 엔진들은 다양하지만 그 중 가장 이용률이 높고, 무료이며 정확도도 가장 높다. 사용의 난이도도 쉬운 편이어서 선택. | ||
| + | :Django: 메뉴/재료 그리고 회원 데이터의 관리 및 검색과 API 통신, 그리고 Tesseract와의 연동을 위한 라이브러리가 제공되기 때문에 선택. | ||
| + | :React JS: Front-end 구현 시 많이 사용하는 component의 재사용에서 편의를 고려해 선택. | ||
| + | :SCSS: Nesting 형태로 구현 가능한 점 때문에 CSS보다 사용이 쉽고, 변수를 사용했을 때의 편의를 고려해 선택. | ||
| + | |||
| + | ===시스템 설계=== | ||
| + | :공공데이터 베이스에서 제공되는 API는 아래와 같이 음식명/재료명이 분리되어있다. 하지만 서비스에서는 음식명과 재료명을 함께 return해야하므로 데이터 모델을 새롭게 정의해야할 필요가 있었다. | ||
| + | :[[파일:일지도 시스템 설계 (1).PNG]] | ||
| + | :위 두 데이터를 결합하여 다음과 같이 재정의했다. | ||
| + | :[[파일:일지도 시스템 설계 (2).PNG]] | ||
| + | :새롭게 정의한 데이터를 DB에 저장하고, Django에서 제공되는 쿼리 필터, Q필터, ORM을 사용해 음식의 데이터를 분리/추출하여 return했다. | ||
| + | :ORM은 Object Relational Mapping(객체-관계 매핑)의 준말로, 객체와 관계형 DB의 데이터를 자동으로 매핑(연결)해주는 것을 말한다. 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용해 생기는 모델 간 불일치를 ORM을 통해 SQL을 자동 생성함으로서 해결한다. | ||
| + | |||
| + | :Tesseract를 이용해 이미지를 입력받으면 API를 이용해 처리한 다음 나온 텍스트 결과를 통해 사용자가 관련 내용을 검색할 수 있도록 한다. | ||
===이론적 계산 및 시뮬레이션=== | ===이론적 계산 및 시뮬레이션=== | ||
| − | |||
| − | === | + | ===소프트웨어 설계=== |
| − | + | :[[파일:일지도 소프트웨어 설계 (1).png]] | |
| + | :Django는 DB의 하나인 SQLite를 포함한다. 하나의 파일에 데이터를 저장하여 쉽고 간편하게 사용할 수 있다는 점이 특징이다. | ||
| + | :Django는 모델로 데이터를 관리한다. 일반적으로는 SQL 쿼리문을 이용해 데이터를 저장/조회하기 때문에, SQL 쿼리문에 대해 추가적으로 학습해야 한다. 하지만 모델을 사용하면 학습 없이 데이터를 관리할 수 있다 (쿼리는 DB에 정보를 요청하는 것) | ||
| + | :공공데이터 포탈과 API 통신을 이용해 가져온 데이터를 모델 형태로 가공해 DB에 저장한다. | ||
| + | :[[파일:일지도 소프트웨어 설계 (2).PNG]] | ||
==결과 및 평가== | ==결과 및 평가== | ||
===완료 작품의 소개=== | ===완료 작품의 소개=== | ||
====프로토타입 사진 혹은 작동 장면==== | ====프로토타입 사진 혹은 작동 장면==== | ||
| − | + | :[[파일:일지도 완료 (1).png]] | |
| − | + | :[[파일:일지도 완료 (2).png]] | |
| − | + | :[[파일:일지도 완료 (3).png]] | |
| + | :[[파일:일지도 완료 (4).png]] | ||
| + | :[[파일:일지도 완료 (5).png]] | ||
| + | :[[파일:일지도 완료 (6).png]] | ||
| + | :[[파일:일지도 완료 (7).png]] | ||
| − | === | + | ===완료작품의 평가=== |
| − | + | [[파일:일지도 평가항목.PNG]] | |
| + | ====어려웠던 내용들==== | ||
| + | :1) 알레르기 유발 음식 데이터 관리 | ||
| + | :프로젝트 초반, 유저들의 데이터를 관리하기 위한 설계에서 어려움을 겪었다. | ||
| + | :매 사용자마다 90종에 해당하는 재료 데이터를 모두 bool 값으로 저장하려고 했다. 그러나 API로 받아온 데이터의 음식명과 재료에 부합하게 설정하는 것이 어려웠고, 초기값 생성 시에 낭비되는 것들도 많았다. | ||
| + | :그래서 사용자의 ID와 알레르기 데이터를 CharField로 생성해 직접 타이핑하여 추가하도록 했다. 처음부터 모든 재료 데이터에 관리할 필요가 없다는 점에서 이득이지만, 미리 설정한 알레르기 유발 음식 후보에 없는 것도 작성할 수 있다는 점에서 개선이 필요하다. | ||
| − | + | :2) Tesseract 사용을 위한 이미지를 받는 과정 | |
| − | + | :이미지를 base64로 인코딩한 값을 전달한 다음 디코딩해야하는데, 이를 한 번의 요청만으로 하기는 어려웠다. 그래서 HyperlinkedModelSerializer 라이브러리를 이용해 image 파일을 저장하고, 이 때 GetImage Table에 id를 같이 생성해 image 파일명을 기억하게 했다. 이 id를 read하고 Tesseract를 작동시키고 추출한 str 데이터를 filter 모델에 삽입해 food 데이터로 추출했다. | |
| + | :사진의 밝기/크기와 기울기 등에 따라 인식의 정확도에 차이가 커서 그 정도를 감안해 촬영한 이미지만을 받기로 했다. | ||
| + | |||
| + | :3) Back-end와 Front-end 간의 연동 | ||
| + | :프로젝트 초기, Back-end에 대한 이해가 이루어지지 않아 Front-end를 Back-end에서 구현했다. API 통신을 하지 않을 경우 페이지를 렌더링할 때 필요한 데이터는 문자열 및 쿼리 형태로 바로 전달 가능하지만, React와 연동함으로서 Json이나 XML 파일로 전환하여 제공하여야 했고 그것을 도와주는 rest API를 재학습하는데 시간이 많이 소요되었다. | ||
| + | |||
| + | :4) Amazon Web Service 배포 | ||
| + | :Back-end에서는 AWS light sail, Front-end에서는 AWS amplify를 이용해서 배포를 진행했다. 하지만 두 방법이 서로 다른 프로토콜(각각 http/https)을 사용해 연동에 문제가 생겼다. Front-end 배포에 http 프로토콜을 사용하는 AWS s3로 변경해 적용시켜 문제를 해결했다. | ||
===향후계획=== | ===향후계획=== | ||
| − | + | :React에서 받아온 검색 내용을 사용자의 국적에 따라 파파고 API와 연동해 번역하여 제공할 수 있는 기능 구현 예정. | |
| − | + | :Front-end에서 입력받은 이미지를 Back-end로 전송해 OCR 기능을 실제로 사용할 수 있도록 구현 예정. | |
| − | |||
| − | |||
2021년 7월 1일 (목) 10:24 기준 최신판
프로젝트 개요
기술개발 과제
국문 : 메뉴별 식재료 데이터 제공 서비스
영문 : (Food Ingredients Data Offering Web Service)
과제 팀명
일지도
지도교수
홍의경 교수님
개발기간
2021년 3월 ~ 2021년 6월 (총 4개월)
구성원 소개
서울시립대학교 컴퓨터과학부 20149200** 이*엽(팀장)
서울시립대학교 컴퓨터과학부 20159200** 허*경
서울시립대학교 컴퓨터과학부 20159200** 게를*****
서울시립대학교 컴퓨터과학부 20189200** 손***
서론
개발 과제의 개요
개발 과제 요약
- 외지에서 언어/문화/종교 등의 장벽을 넘어 식사 메뉴를 결정하는 것은 어려운 일이다. 한국에서 생활하는 외국인들에게 좀 더 쉽고 넓은 선택의 폭을 제공하고, 더 나아가서 한국인들도 외국에 나가서 사용할 수 있는 서비스를 제공하는 것이 목표인 프로젝트이다.
개발 과제의 배경 및 효과
- 팀‘일지도’에는 2명의 유학생이 있다. 그들을 포함한 많은 수의 대한민국 내 거주 외국인들은 고국과 전혀 다른 문화에서 살면서 여러 어려움을 겪는다.
- 그 중 하나는 매일매일 식사를 위해 메뉴를 정하는 것이다. 한국인 역시 어려움을 겪는 부분이지만, 외국인들의 그것과는 엄연히 다르다. 단순히 그 날의 기분이나 취향에 따른 선택의 문제가 아니기 때문이다.
- 물론 음식에 들어가는 재료에 대한 선호 여부도 중요하지만, 알레르기를 유발하는 식품이 사용되지 않았는지도 중요하다. 거기에 더해 종교적/신념적 이유로 먹지 않는 것이 있을 수도 있다. 이슬람교에서 돼지고기가 금기음식이라는 점, 채식주의자도 허용 식품에 따라 분류된다는 점이 그 예시이다.
- 한글을 사용하고, 한국 문화와 음식에 익숙한 우리도 앞서 말한 모든 기준을 고려해 메뉴를 정하는 것은 어렵고 귀찮은 일이다. 하물며 외국인에게는 어떻겠는가. 그래서 우리는 손쉽게 음식 이름만 입력하면 관련 정보를 제공하는 프로그램을 만들기로 결정했다.
개발 과제의 목표 및 내용
- 사용자의 외국어 구사 능력과 상관 없이, 선호/알레르기/종교/신념 등 다양한 조건에 따라 원하는 메뉴를 검색할 수 있다.
관련 기술의 현황
관련 기술의 현황 및 분석(State of art)
- [Optical Character Recognition(OCR)]
- 광학 문자 인식(OCR)은 사람이 쓰거나 기계로 인쇄한 문자의 영상을 이미지 스캐너로 획득하여 기계가 읽을 수 있는 문자로 변환하는 것이다.
- 이미지 스캔으로 얻을 수 있는 문서의 활자 영상을 컴퓨터가 편집 가능한 문자코드 등의 형식으로 변환하는 소프트웨어로써 일반적으로 OCR이라고 하며, OCR은 인공지능이나 기계 시각(machine vision)의 연구분야로 시작되었다.
기술 로드맵
- OCR 엔진 및 종류: Tesseract, easyOCR, Ocropus, Kraken 네이버 클라우드 플랫폼 OCR 등
- [Tesseract]
- 다양한 OS를 위한 광학 문자 인식 엔진이다. 무료 소프트웨어이며 2006년부터 Google에서 개발을 후원했다.
- Linux, Windows 및 Mac OSx에서 사용할 수 있다. 초기 버전은 영어 텍스트만 인식할 수 있었지만 현재는 100개 이상의 언어를 지원한다.
- [네이버 클라우드 플랫폼 OCR]
- 네이버 AI 기술을 활용한 고성능 OCR 인식 모델을 적용했다. 문자 인식은 한국어/영어/일본어, 필기체 인식은 한국어/일본어를 지원한다.
시장상황에 대한 분석
경쟁제품 조사 비교
- 망치(mangchi.com), 코리안 밥상(koreanbapsang.com), 코리아 테이스트(koreataste.org), 서울이츠(seouleats.com) 등 한국의 식당을 추천하거나 음식 레시피를 소개하는 사이트는 많다. 하지만 알레르기 유발/기호/종교/신념 등 다양한 조건에 따라 메뉴를 검색하는 서비스는 없는 것으로 보인다. 앞서 예시를 든 사이트 내에서 각 재료 혹은 메뉴를 모두 검색해서 찾을 수도 있겠지만 상당히 번거롭고 힘든 일일 것이다.
마케팅 전략 제시
- Strength
- 아직 대중화되지 않은 서비스의 희소성
- 간단한 클릭 몇 번을 통해 쉽게 메뉴 선정 조건을 설정
- 구현/사용이 어렵지 않은 프로젝트
- Weakness
- 구현 과정의 학습 필요로 불확실한 완성도
- 식당마다 다른 메뉴 레시피
- 공공데이터에 존재하지 않는 메뉴가 있을 가능성
- Opportunity
- 손쉬운 메뉴 선정으로 사용자의 다양한 식사 기회 제공
- 다양한 국적의 손님 이용으로 관련 경제 활성화
- Threat
개발과제의 기대효과
경제적, 사회적 기대 및 파급효과
- 사용자 누구나 선호도/알레르기 유발/종교/신념 등 여러 조건을 고려해 음식을 선택할 수 있게 되어 삶의 질이 향상될 것으로 기대된다. 그리고 경제적인 측면에서도, 특히 외국인들이 더 다양한 식당에 방문할 수 있게 되어 긍정적인 효과를 얻을 수 있을 것이라 예상된다. 또 잘못된 메뉴 선택에 따라 발생하는 음식물 쓰레기의 양도 줄어들 것이다.
기술개발 일정 및 추진체계
개발 일정

구성원 및 추진체계
- 이상엽: 기획, 예산 관리, 사무 등
- 허가경: 데이터베이스 구축 및 API 가공/저장
- 게를 사이칸 무릉: OCR 기능 구현 및 연동
- 손도수렝: CSS/그래픽 인터페이스 구현, React/파이썬 연동 구현
설계
설계사양
사용자 요구사항
- 데이터 검색: 한 메뉴가 어떤 재료로 만들어졌는지, 혹은 특정 재료가 들어간 음식에는 무엇이 있는지 등에 대해 검색한다.
- 데이터 추가/수정/삭제: 서비스의 데이터베이스에 존재하지 않는 메뉴에 대한 정보를 추가, 혹은 기존 데이터에 대한 정보를 수정/삭제한다.
- 사진 인식: 모르는 언어로 된 메뉴판 등을 사진으로 찍어 번역한다.
- 회원가입을 통한 서비스의 개인화: 회원가입 후 검색 조건을 저장해 개인화된 서비스를 이용한다.
- 회원탈퇴: 회원탈퇴를 통해 저장된 개인 정보를 삭제한다.
- 비회원 사용: 회원가입 없이 서비스만 이용할 수 있다.
사용자 요구사항 만족을 위한 기능 정의
- 데이터 검색: 알레르기 유발/기호/종교/신념 등 다양한 조건을 설정한다. 그 다음 메뉴명을 검색해 구성 재료를 알아볼 수 있고, 재료명을 검색해 해당 재료가 들어간 메뉴를 알아볼 수 있다.
- 데이터 추가/수정/삭제: 관리자 혹은 사용자가 데이터를 직접 추가/수정/삭제할 수 있다.
- 사진 인식: OCR을 이용해 사진에서 문자/숫자를 인식해 텍스트로 추출하여 검색에 이용할 수 있다.
- 회원가입을 통한 서비스의 개인화: ID/PW/이메일 등의 정보를 이용해 회원가입하고, 검색 시 설정한 조건을 해당 계정에 저장할 수 있다.
- 회원탈퇴: 회원탈퇴를 하여 저장된 개인 정보를 삭제할 수 있다.
- 비회원 사용: 비회원도 검색 조건 저장을 제외한 서비스를 이용할 수 있다.
기능 구현을 위한 세부기술 선택사항(디자인)
- Tesseract: OCR(광학 문자 인식) 기능을 제공하는 엔진들은 다양하지만 그 중 가장 이용률이 높고, 무료이며 정확도도 가장 높다. 사용의 난이도도 쉬운 편이어서 선택.
- Django: 메뉴/재료 그리고 회원 데이터의 관리 및 검색과 API 통신, 그리고 Tesseract와의 연동을 위한 라이브러리가 제공되기 때문에 선택.
- React JS: Front-end 구현 시 많이 사용하는 component의 재사용에서 편의를 고려해 선택.
- SCSS: Nesting 형태로 구현 가능한 점 때문에 CSS보다 사용이 쉽고, 변수를 사용했을 때의 편의를 고려해 선택.
시스템 설계
- 공공데이터 베이스에서 제공되는 API는 아래와 같이 음식명/재료명이 분리되어있다. 하지만 서비스에서는 음식명과 재료명을 함께 return해야하므로 데이터 모델을 새롭게 정의해야할 필요가 있었다.
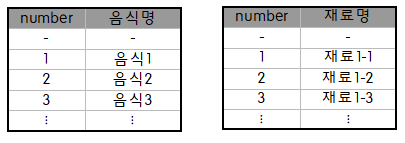
- 위 두 데이터를 결합하여 다음과 같이 재정의했다.
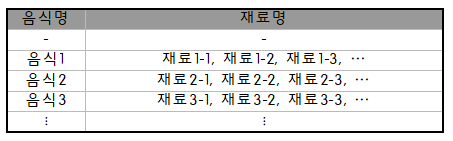
- 새롭게 정의한 데이터를 DB에 저장하고, Django에서 제공되는 쿼리 필터, Q필터, ORM을 사용해 음식의 데이터를 분리/추출하여 return했다.
- ORM은 Object Relational Mapping(객체-관계 매핑)의 준말로, 객체와 관계형 DB의 데이터를 자동으로 매핑(연결)해주는 것을 말한다. 객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용해 생기는 모델 간 불일치를 ORM을 통해 SQL을 자동 생성함으로서 해결한다.
.PNG)
.PNG)
- Tesseract를 이용해 이미지를 입력받으면 API를 이용해 처리한 다음 나온 텍스트 결과를 통해 사용자가 관련 내용을 검색할 수 있도록 한다.
이론적 계산 및 시뮬레이션
소프트웨어 설계
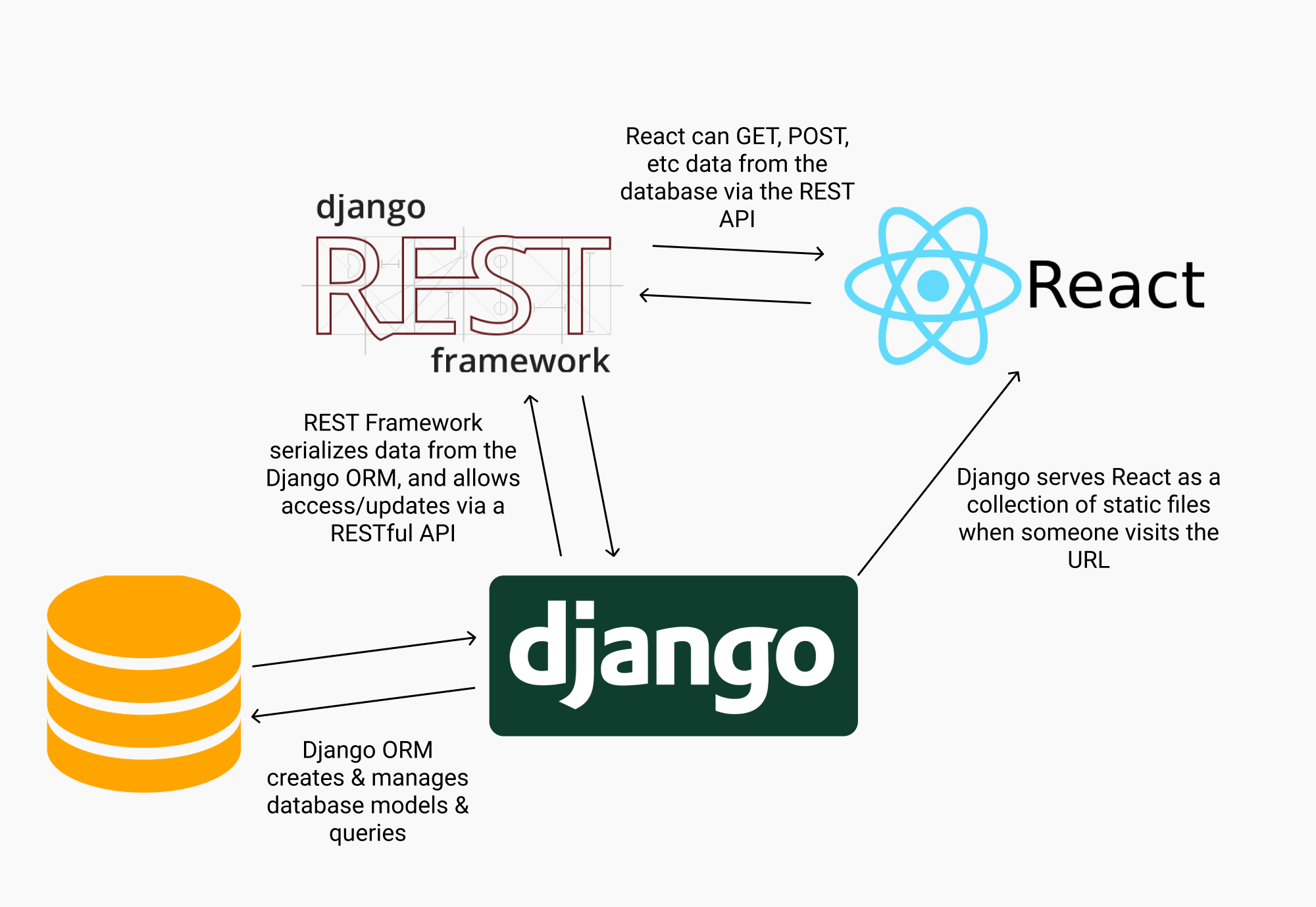
- Django는 DB의 하나인 SQLite를 포함한다. 하나의 파일에 데이터를 저장하여 쉽고 간편하게 사용할 수 있다는 점이 특징이다.
- Django는 모델로 데이터를 관리한다. 일반적으로는 SQL 쿼리문을 이용해 데이터를 저장/조회하기 때문에, SQL 쿼리문에 대해 추가적으로 학습해야 한다. 하지만 모델을 사용하면 학습 없이 데이터를 관리할 수 있다 (쿼리는 DB에 정보를 요청하는 것)
- 공공데이터 포탈과 API 통신을 이용해 가져온 데이터를 모델 형태로 가공해 DB에 저장한다.

.png)
.PNG)
결과 및 평가
완료 작품의 소개
프로토타입 사진 혹은 작동 장면
.png)
.png)
.png)
.png)
.png)
.png)
.png)
완료작품의 평가

어려웠던 내용들
- 1) 알레르기 유발 음식 데이터 관리
- 프로젝트 초반, 유저들의 데이터를 관리하기 위한 설계에서 어려움을 겪었다.
- 매 사용자마다 90종에 해당하는 재료 데이터를 모두 bool 값으로 저장하려고 했다. 그러나 API로 받아온 데이터의 음식명과 재료에 부합하게 설정하는 것이 어려웠고, 초기값 생성 시에 낭비되는 것들도 많았다.
- 그래서 사용자의 ID와 알레르기 데이터를 CharField로 생성해 직접 타이핑하여 추가하도록 했다. 처음부터 모든 재료 데이터에 관리할 필요가 없다는 점에서 이득이지만, 미리 설정한 알레르기 유발 음식 후보에 없는 것도 작성할 수 있다는 점에서 개선이 필요하다.
- 2) Tesseract 사용을 위한 이미지를 받는 과정
- 이미지를 base64로 인코딩한 값을 전달한 다음 디코딩해야하는데, 이를 한 번의 요청만으로 하기는 어려웠다. 그래서 HyperlinkedModelSerializer 라이브러리를 이용해 image 파일을 저장하고, 이 때 GetImage Table에 id를 같이 생성해 image 파일명을 기억하게 했다. 이 id를 read하고 Tesseract를 작동시키고 추출한 str 데이터를 filter 모델에 삽입해 food 데이터로 추출했다.
- 사진의 밝기/크기와 기울기 등에 따라 인식의 정확도에 차이가 커서 그 정도를 감안해 촬영한 이미지만을 받기로 했다.
- 3) Back-end와 Front-end 간의 연동
- 프로젝트 초기, Back-end에 대한 이해가 이루어지지 않아 Front-end를 Back-end에서 구현했다. API 통신을 하지 않을 경우 페이지를 렌더링할 때 필요한 데이터는 문자열 및 쿼리 형태로 바로 전달 가능하지만, React와 연동함으로서 Json이나 XML 파일로 전환하여 제공하여야 했고 그것을 도와주는 rest API를 재학습하는데 시간이 많이 소요되었다.
- 4) Amazon Web Service 배포
- Back-end에서는 AWS light sail, Front-end에서는 AWS amplify를 이용해서 배포를 진행했다. 하지만 두 방법이 서로 다른 프로토콜(각각 http/https)을 사용해 연동에 문제가 생겼다. Front-end 배포에 http 프로토콜을 사용하는 AWS s3로 변경해 적용시켜 문제를 해결했다.
향후계획
- React에서 받아온 검색 내용을 사용자의 국적에 따라 파파고 API와 연동해 번역하여 제공할 수 있는 기능 구현 예정.
- Front-end에서 입력받은 이미지를 Back-end로 전송해 OCR 기능을 실제로 사용할 수 있도록 구현 예정.