"SDA"의 두 판 사이의 차이
cdc wiki
(→완료작품의 평가) |
(→관련 기술의 현황 및 분석(State of art)) |
||
| (같은 사용자의 중간 판 2개는 보이지 않습니다) | |||
| 67번째 줄: | 67번째 줄: | ||
: 버튼의 입력정보를 전송하는 TV리모콘 및 상기 TV리모콘과 무선으로 연결되어 있으며, 상기 TV리모콘으로부터 상기 입력정보를 수신하고, 상기 스마트폰의 입력정보를 분석하여 상기 TV리모콘 사용자의 신변에 변화가 발생한 것으로 판단되는 경우 지정된 연락처로 통보하는 스마트폰을 포함 | : 버튼의 입력정보를 전송하는 TV리모콘 및 상기 TV리모콘과 무선으로 연결되어 있으며, 상기 TV리모콘으로부터 상기 입력정보를 수신하고, 상기 스마트폰의 입력정보를 분석하여 상기 TV리모콘 사용자의 신변에 변화가 발생한 것으로 판단되는 경우 지정된 연락처로 통보하는 스마트폰을 포함 | ||
3. 기술 로드맵 | 3. 기술 로드맵 | ||
| − | * | + | * Step 1 |
: AI 단말기 백그라운드에서 실행 | : AI 단말기 백그라운드에서 실행 | ||
: 카메라를 제어하여 실시간 영상(이미지 프레임)을 수집 | : 카메라를 제어하여 실시간 영상(이미지 프레임)을 수집 | ||
: 앱 내에 이식시킨 딥러닝 모델에 수집한 영상(이미지 프레임)을 입력 | : 앱 내에 이식시킨 딥러닝 모델에 수집한 영상(이미지 프레임)을 입력 | ||
| − | * | + | * Step 2 |
: 인간 객체를 탐지하여 Skeleton으로 벡터화 | : 인간 객체를 탐지하여 Skeleton으로 벡터화 | ||
: 딥러닝 모델 3개를 모두 통과시켜 행동분류 진행 | : 딥러닝 모델 3개를 모두 통과시켜 행동분류 진행 | ||
: 행동분류 후 결과를 앱에 전달 | : 행동분류 후 결과를 앱에 전달 | ||
| − | * | + | * Step 3 |
: 행동인식 결과가 위험상황일 시 보호자 앱에 알림 전송 | : 행동인식 결과가 위험상황일 시 보호자 앱에 알림 전송 | ||
: 알림을 통해 위험상황을 인식한 보호자(or 도우미)는 위험상황 대처 시작 | : 알림을 통해 위험상황을 인식한 보호자(or 도우미)는 위험상황 대처 시작 | ||
| 367번째 줄: | 367번째 줄: | ||
===완료작품의 평가=== | ===완료작품의 평가=== | ||
* 평가 기준 | * 평가 기준 | ||
| − | [[파일:평가기준표.png]] | + | :[[파일:평가기준표.png]] |
* 평가 결과 | * 평가 결과 | ||
:# 분류 정확도 | :# 분류 정확도 | ||
| − | [[파일:분류정확도.png]] | + | :#:[[파일:분류정확도.png]] |
:# 모델 속도 | :# 모델 속도 | ||
| − | [[파일:모델 속도.png]] | + | :#:[[파일:모델 속도.png]] |
:# 응답 시간 | :# 응답 시간 | ||
| − | [[파일:응답시간.png]] | + | :#:[[파일:응답시간.png]] |
* 평과 결과 분석 | * 평과 결과 분석 | ||
:'''분류 정확도''' | :'''분류 정확도''' | ||
| 380번째 줄: | 380번째 줄: | ||
:낙상에 대한 분류 정확도를 전,후,좌,우 방향으로 나누어 테스트를 진행하였다. 좌,우에 비해서 전,후의 정확도가 더 낮은 것을 확인할 수 있었다. 이는 1차적으로 스켈레톤 구조를 추출하는 Pose Detection API의 한계였다. Pose Detection API는 얼굴로 인간 객체를 찾고, 얼굴을 기반으로 나머지 관절 정보를 추출한다. 하지만 전방, 후방으로 낙상을 하는 경우에는 카메라에 얼굴이 잘 안보이는 경우가 많았고, 이 때문에 아예 관절 정보를 추출하지를 못하였다. 이러한 경우 때문에 전,후방의 정확도가 좌,우에 비해서 낮았다. 좌,우로 넘어지는 경우에는 전,후방에 비해 얼굴이 카메라에 나와 객체를 잘 탐지할 확률이 확실히 높아 낙상을 잘 인지하였지만, 관절 정보를 추출할 수 없을 정도로 얼굴이 보이지 않는 경우가 있어 낙상으로 인지되지 않을 때가 있었다. | :낙상에 대한 분류 정확도를 전,후,좌,우 방향으로 나누어 테스트를 진행하였다. 좌,우에 비해서 전,후의 정확도가 더 낮은 것을 확인할 수 있었다. 이는 1차적으로 스켈레톤 구조를 추출하는 Pose Detection API의 한계였다. Pose Detection API는 얼굴로 인간 객체를 찾고, 얼굴을 기반으로 나머지 관절 정보를 추출한다. 하지만 전방, 후방으로 낙상을 하는 경우에는 카메라에 얼굴이 잘 안보이는 경우가 많았고, 이 때문에 아예 관절 정보를 추출하지를 못하였다. 이러한 경우 때문에 전,후방의 정확도가 좌,우에 비해서 낮았다. 좌,우로 넘어지는 경우에는 전,후방에 비해 얼굴이 카메라에 나와 객체를 잘 탐지할 확률이 확실히 높아 낙상을 잘 인지하였지만, 관절 정보를 추출할 수 없을 정도로 얼굴이 보이지 않는 경우가 있어 낙상으로 인지되지 않을 때가 있었다. | ||
:딥러닝 모형 기반인 2차 판단의 성능은 train_set과 test_set에서 정확도는 0.9971, 0.9961로 높은 성능을 보였다. 하지만, 이는 잘 구성된 학습 데이터 상에서의 성능이였고, 실제 AI 단말기에서 촬영된 영상을 가지고 여러가지 행동을 취해보며 성능을 측정했다. 기존의 학습 데이터에서 존재했던 47개의 행동 종류 외의 다른 행동을 취했을 경우 모델이 해당 행동을 잘 처리하지 못하는 문제가 존재했다. 학습 데이터가 수집될 때 사용되었던 카메라의 성능, 각도가 현재 AI 단말기에서 사용되는 카메라와 다르다는 점도 성능 하락의 문제로 생각되었다. 실생활에서 예측할 수없는 수많은 행동들을 잘 분류할 수 있도록, 여러가지 행동들이 있는 대규모 영상 데이터셋을 통해 추가적인 학습이 진행되어야할 것이라고 판단되고, 모델의 최적화를 더 진행하여 강건한 시스템을 만들어야된다고 판단된다. | :딥러닝 모형 기반인 2차 판단의 성능은 train_set과 test_set에서 정확도는 0.9971, 0.9961로 높은 성능을 보였다. 하지만, 이는 잘 구성된 학습 데이터 상에서의 성능이였고, 실제 AI 단말기에서 촬영된 영상을 가지고 여러가지 행동을 취해보며 성능을 측정했다. 기존의 학습 데이터에서 존재했던 47개의 행동 종류 외의 다른 행동을 취했을 경우 모델이 해당 행동을 잘 처리하지 못하는 문제가 존재했다. 학습 데이터가 수집될 때 사용되었던 카메라의 성능, 각도가 현재 AI 단말기에서 사용되는 카메라와 다르다는 점도 성능 하락의 문제로 생각되었다. 실생활에서 예측할 수없는 수많은 행동들을 잘 분류할 수 있도록, 여러가지 행동들이 있는 대규모 영상 데이터셋을 통해 추가적인 학습이 진행되어야할 것이라고 판단되고, 모델의 최적화를 더 진행하여 강건한 시스템을 만들어야된다고 판단된다. | ||
| − | [[파일:평가 결과 분석.png]] | + | :[[파일:평가 결과 분석.png]] |
===어려웠던 점=== | ===어려웠던 점=== | ||
2022년 6월 15일 (수) 18:21 기준 최신판
프로젝트 개요
기술개발 과제
국문 : 일상생활 데이터 분석 기반 시니어 케어 시스템
영문 : Development of Seniar Care System based on Daily Life Data
과제 팀명
SDA (Seniar Danger Analysis)
지도교수
유*진 교수님
개발기간
2022년 3월 ~ 2022년 6월 (총 4개월)
구성원 소개
서울시립대학교 컴퓨터과학부 20179200** 박**(팀장)
서울시립대학교 컴퓨터과학부 20179200** 정**
서울시립대학교 컴퓨터과학부 20169200** 김**
서울시립대학교 통계학과 20175800** 최**
서론
개발 과제의 개요
개발 과제 요약
- 디스플레이형 AI 단말기를 활용하여 65세 이상의 시니어를 대상으로 일상 생활 데이터를 모으고, 앞에서 말한 서비스 중 실시간 행동 분석을 통한 어르신들의 안전 케어 및 위험 상황 판단에 대한 스마트 서비스를 제공하는 시스템을 개발하는 것
개발 과제의 배경
- 초고령 사회 진입이 예상되는 가운데 여러 시니어 케어 시스템이 나오고 있지만 어르신들이 의식을 잃은 상태나, 사망하셨을 때 적절한 기능을 수행하지 못함.
- 노인의 신체 손상 원인 중 절반 이상이 낙상이고 집 등 거주 시설에서 발생하는 경우가 가장 많음.
- 보호자나 도우미들은 공간적 제약 및 물리적 제한이 있어 24시간 종일 관리할 수 없는 현실
- 기존의 실시간 행동 분석을 통한 위험 상황 판단 시스템은 몇 가지 문제점이 있어 성능저하 문제가 존재함.
개발 과제의 목표 및 내용
- 실시간 영상 분석을 통한 어르신의 행동 분류
- AI 단말기의 내장된 카메라로부터 어르신을 탐지하고, 스켈레톤 구조로 변환
- 스켈레톤 구조로 변환된 특징 벡터를 기반으로 영상의 짧은 시간 안에 어르신들의 행동을 분류
- 분류된 행동이 낙상과 같은 위험 행동으로 분류된 경우 알림 전송
- AI 단말기 내 앱 개발 및 리소스 제어
- AI 단말기의 전원을 키면, 앱이 자동적으로 실행
- AI 단말기에 내장된 카메라를 제어하여, 앱 내에서 정해진 시간마다 프레임을 가져와 학습된 모델의 입력으로 변환
- AI 단말기 속의 앱 내에서 발생한 알림을 보호자 앱으로 전송
- 보호자 앱
- AI 단말기 앱에서 등록한 보호자와 연동되도록 보호자 앱을 구현
- 데이터베이스에서 시니어 정보를 가져와 화면에 출력
- AI 단말기 앱으로부터 전송된 알림을 보호자 앱이 설치된 기기의 상단 알림으로 출력
- 알림을 누르면 시니어의 정보와 스토리지에 저장된 이미지를 화면에 출력
관련 기술의 현황
관련 기술의 현황 및 분석(State of art)
1. State of art(Object Detection)
- 2013년에 최초의 딥러닝 기반 Object detection 모델인 R-CNN이 등장한 후, R-CNN 계열의 모델인 Fast R-CNN, Faster RCNN 모델들이 성과를 보여주었음.
- 2016년에는 YOLO와 SSD가 등장하면서 새로운 계열의 딥러닝 기반 모델이 등장
- 2017년에 RetinaNet이 등장하면서 높은 성능을 보여줌.
- 2019년 후반부터 AutoML 기법을 도입한 EfficientNet, EfficientDet 계열이 등장하고, NLP 분야에서 사용되는 Attention 기반의 transformer 기법을 도입한 DERT 모델 계열이 등장
- 처리 속도는 빠르지만 정확도에서의 한계점을 지닌 YOLO 계열의 모델이 version4, 5를 거듭하여 속도뿐만 아니라 높은 정확도를 가지며 다시금 객체 탐지 분야에서의 존재를 입증
- 그 이후에도 성능을 발전시킨 Swin Transformer 기반 모델이 등장하였고, 객체 탐지 분야의 성능 평가인 AP 지표가 60을 넘기는 발전을 기록함.
2. 특허 조사
- 독거노인 케어 시스템
- (법정상태 : 거절, 심사진행상태 : 거절결정(재심사))
- 급작스러운 신체적 문제 발생에 따라 독거노인이 스스로 자신의 상황을 전달할 수 없는 형편인 경우에도 독거노인의 이상징후를 스스로 판단하여 이상결정시 이를 관리주체에 통보할 수 있는 독거노인 케어 시스템
- 노인이 거주하는 세대 내에 설치되는 전기기기 스위치의 온(ON)/오프(OFF) 상태정보를 감시하고, 온/오프 상태정보와 전기기기 스위치의 신원정보를 함께 제공하는 통신부를 갖는 세대 별 감시통신장치
- 리모콘을 이용한 위험 관리 시스템
- (공개특허공보)
- 버튼의 입력정보를 전송하는 TV리모콘 및 상기 TV리모콘과 무선으로 연결되어 있으며, 상기 TV리모콘으로부터 상기 입력정보를 수신하고, 상기 스마트폰의 입력정보를 분석하여 상기 TV리모콘 사용자의 신변에 변화가 발생한 것으로 판단되는 경우 지정된 연락처로 통보하는 스마트폰을 포함
3. 기술 로드맵
- Step 1
- AI 단말기 백그라운드에서 실행
- 카메라를 제어하여 실시간 영상(이미지 프레임)을 수집
- 앱 내에 이식시킨 딥러닝 모델에 수집한 영상(이미지 프레임)을 입력
- Step 2
- 인간 객체를 탐지하여 Skeleton으로 벡터화
- 딥러닝 모델 3개를 모두 통과시켜 행동분류 진행
- 행동분류 후 결과를 앱에 전달
- Step 3
- 행동인식 결과가 위험상황일 시 보호자 앱에 알림 전송
- 알림을 통해 위험상황을 인식한 보호자(or 도우미)는 위험상황 대처 시작
시장상황에 대한 분석
- 경쟁제품 조사 비교
- 실시간 행동 분석 및 객체 탐지 기술 제품
- 신한은행은 보이스피싱의 타깃이 된 고령 고객의 금융자산을 보호하기 위한 특단의 대책으로 은행권 처음으로 ‘AI 이상행동 탐지 ATM’을 도입
- SKT는 AI 기반 지능형 영상분석 솔루션을 상반기 출시할 예정이며, 자체 AI칩으로 개발을 할 계획
- 교통 분야에서는 2020년 ‘주차유도’ 기술을 상용화해 영상 내 주차 공간을 인식해 사용자에게 주차 자리 빈 곳을 알려주고, 안정적인 주차를 유도
- 운전자 모습을 영상으로 실시간 촬영해 위험 여부를 알려주는 ‘안전운전 보조 솔루션’존재
- 시니어 케어 서비스 제품
- 노년층을 위한 ‘시니어 맞춤형 서비스’가 다양한 산업군에서 쏟아지고 있음.
- 한글과컴퓨터는 시니어 케어 서비스 사업에 진출하여 ‘한컴 말랑말랑 행복케어’를 통해 인지훈련 치매 예방 가상현실(VR)과 상호교감이 가능한 AI 로봇 활용 프로그램도 제공할 예정.
- SKT는 자사의 AI 스피커인 ‘누구(NUGU)’를 통해 시니어 케어 서비스를 제공하고 있는데 이를 통해 거동이 불편한 어르신들이 음성을 통해 119 호출을 할 수 있는 기능과 말동무 기능 등을 선보임.
- KT와 LGU+에서도 시니어 케어 사업에 적극적인 태도를 취하고 있는 것으로 나타남.
- 실시간 행동 분석 및 객체 탐지 기술 제품
- 마케팅 전략 제시
- 보호자나 도우미들의 도움이 있더라도 시공간적 제약 및 물리적 제한이 있어 24시간 종일 관리할 수는 없는 상황
- 기존의 디스플레이형 AI 단말기에 있는 카메라를 통해 실시간으로 어르신들의 위험 상황을 판별하고, 이를 보호자에게 알림을 주는 시스템(앱)을 개발하여 사회문제를 해결하고자 함.
- 여러 장비가 필요하지 않은 점과 행동분류모델이 빠르다는 점은 어르신들을 돌보는 입장인 보호자, 도우미, 지자체 쪽에 좋은 선택지가 될 것.
개발과제의 기대효과
기술적 기대효과
- AI 단말기 내에서 프레임 추출, 행동 분류, 알림 전송 기능을 실행하고 처리하는 형식으로 구현하여 병목 현상을 방지할 수 있을 것이다. 이러한 면에서 많은 사용자들을 수용할 수 있는 수용력을 가진다. 또한 일련의 진행과정에서 서버와의 통신과정이 제외되기 때문에 시간이 단축될 것이다.
경제적, 사회적 기대 및 파급효과
- AI 단말기가 시니어들의 주거공간에 보급되고 있는 가운데, 여러 기기들에서 처리하는 것이 아닌, 해당 단말기를 통해 서비스를 제공하므로 추가적인 단말기 구입 비용이 절약된다.
- 앱 내에서 진행되는 서비스 특성상 서버 구현에 드는 비용도 없다.
- 현재 국가 주도 및 지자체에서 어르신들의 건강 관리 및 위험 상황들을 파악 및 예방, 대처하려는 노력을 하고 있다. 이에 관련지어, 일상생활에서 어르신들의 위험상황을 탐지하고 보호자에게 알림을 주어 빠른 대처가 가능할 것이고 한계가 정해져있는 예산 안에서 많은 노인분들을 케어하는 입장인 지자체에게 좋은 선택지가 될 것이다.
기술개발 일정 및 추진체계
개발 일정

구성원 및 추진체계
- 구성원

- 추진체계

설계
설계사양
제품의 요구사항
- 죽지 않는 서비스를 구현
- 단말기 카메라를 이용하여 매 초마다 일정 개수의 이미지를 수집
- 보호자 정보를 설정
- 위험 상황 판단 시, 보호자에게 알림 전송
- 학습모델을 단말기 내에서 실행될 수 있도록 이식
- 영상처리를 통해 인간 객체를 스켈레톤화
- 스켈레톤화된 데이터를 딥러닝을 가지고 행동분류
- 학습 모델의 처리 속도가 10초 이하가 되도록 구현
- 카메라가 비추지 못하는 구역을 소음분류를 통해 판단
- 이미지를 주기적으로 저장/삭제
- 단말기에서 보호자 측으로 보내는 알림이 5초 안에 송신
- 분류해야하는 행동의 종류를 5개 이상
개념설계안
가. 죽지않는 서비스
- 서비스는 앱이 UI 없이 백그라운드에서 특정 시간 동안 실행되는 것을 의미한다. 많은 앱은 서비스를 데이터 처리, 연산 등에서 많이 사용한다. 일반적인 안드로이드 앱들은 죽지 않는 서비스(Immortal Service)를 주로 이용한다. 왜냐하면, 백그라운드 서비스는 OS가 Task Kill을 해서 서비스를 종료시켜버릴 수 있지만 죽지 않는 서비스는 여기에서 서비스가 종료되었을 때, 다시 서비스를 재실행시키는 방식으로 구현하여 서비스가 완전히 종료되지 않도록 하기 때문이다.
- 죽지 않는 서비스의 구현은 일반적인 서비스를 구현하는 것과 비슷하지만 차이점이 존재한다. 먼저 서비스를 실행시키고 서비스가 어떠한 조건으로 죽으면 알람을 통해 다시 startService 메서드를 사용, 서비스를 재실행시킨다. 제일 중요하게 처리해야 하는 조건은 위의 문단에서 말했던 OS가 서비스를 죽이는 경우이다. 앱을 종료하거나 내리거나 화면을 끄는 경우는 서비스의 특성상 괜찮지만 OS가 서비스를 죽이는 경우에는 서비스가 시작돼야 하는 단이 백그라운드이기 때문에 조금 더 복잡하다. 지금 안드로이드 버전이 Snow Cone(12.1)까지 나왔는데 안드로이드 Oreo(8.0) 이후 버전에서는 서비스를 백그라운드에서 실행하는 것을 금지하기 때문에 포그라운드에서 실행해야 한다. 그래서 죽지 않는 서비스를 구현할 때 startForegroundService 메서드라는 한 가지 과정이 더 필요하지만, 우리가 사용하는 단말기의 버전은 Oreo 이전 버전(7.1)이기 때문에 startService 메서드와 리시버만 가지고 죽지 않는 서비스를 구현할 수 있다. 이외의 죽지 않는 서비스를 위하여 구현이 필요한 부분은 재부팅 시 서비스 자동 실행이다. 이 부분은 브로드캐스트리시버를 사용하여 액션을 받아 현재 부팅이 되었다는 것을 인식하면 startService를 실행시키는 것으로 해결할 수 있다.

나. 영상에서의 행동 인식
- 영상을 입력받으면, 영상을 실시간 행동 분석이 가능한 프레임 수로 나누어 인간 객체를 Skeleton으로 벡터화시키는 과정을 진행한다. 이때, OpenPose 모델 중 18개의 관절 정보를 출력하는 COCO 모델을 사용한다.


- OpenPose 모델을 거친 영상은 프레임별로, 인간 객체의 골격 위치 정보를 저장할 수 있다. 이러한 정보를 곧바로 모델의 입력에 사용할 수 있지만, 2차원의 관절 정보로는 분류 정확도가 낮음을 확인했다. 실제로, 실시간 행동 인식 모형의 State of Art는 Kinetic 카메라로부터 얻어진 RGB+D 영상을 기준으로 처리하는 모형이 많다. 하지만, 실제 AI 단말기 내에서 사용되는 카메라는 RGB를 출력하는 일반 카메라로, 분류 성능을 위한 정보의 양이 한정되어있다.

- 이러한 문제를 해결하기 위해, deep-learning 기반 모델로 주어진 2D 관절 좌표를 3차원으로 매핑해주는 오픈소스인 3D-Pose-Baseline을 이용한다. 이는 RGB 카메라에서 얻은 정보를 3차원 공간정보로 바꾸어주는 과정을 추가하여, 카메라의 성능 개선 부담을 줄이면서, 정보의 양은 늘리는 효과를 가진다.
- 즉, 앞선 두 과정을 파이프라인으로 설정하여, 입력 데이터가 들어오면, 프레임별로 2D-Skeleton 정보를 추출하고 이를 3D-Skeleton 정보로 변환하는 과정을 거치게 된다.
- 입력 파이프라인을 거친 3D 공간정보는 행동 분류 모델의 입력이 된다. 행동 분류 모델은ST-GCN(Spatial Temporal Graph Convolutional Networks)을 사용한다.

- 어르신들의 70세 이상의 고령자 53명의 자택을 방문하여 기상부터 취침까지의 하루 행동을 직접 관찰한 데이터에서 245개의 일상 활동 유형 중 빈번하게 나타나는 행동으로 TV 시청, 식사 관련 활동, 화장실 사용, 식사 준비, 전화 통화, 약 복용, 요리, 청소 등이 있었으며 이러한 다빈도 활동들을 기준으로 55종의 행동을 인식 대상으로 선정한다. 해당 라벨들을 분류 모형의 예측 클래스가 되며, 각 행동들에 대한 로짓값을 출력하도록 한다. 이 중 쓰러지기와 같은 일부 행동을 이상 행동(위험 행동)으로 분리하여, 최종적으로 어르신이 취하고 있는 행동이 정상 행동인지, 이상 행동인지를 출력한다.
다. AI 단말기 내에서 실행되는 실시간 행동분석
- 앞의 두 가지 개념을 이용해서 결과적으로 다음과 같은 시스템을 만들고자 한다.

- 실시간 행동 분석을 위해, AI 단말기의 전원을 켜면 단말기 내의 카메라를 제어하여 영상(또는 프레임)을 자동으로 수집하여, 윈도우 환경에서 학습한 입력 파이프라인과 행동 분류 모델의 입력으로 넣는다.

- 실시간 영상(일정 프레임)에서의 행동을 분류하기 위해, 입력 이미지의 개수(프레임의 개수)를 30개로 제한하여 매 30 프레임마다 어떤 행동인지 판단하게 된다. 윈도우 환경에서 작성한 모델은 텐서플로 라이트로 변환 후 이식을 진행한다. 모델 과정의 출력 중 이상 행동이 검출되면, 사전에 연결된 보호자에게 해당 상황을 설명하는 데이터를 전송한다. 데이터에는 행동 분류에 사용된 영상, 이상 행동 클래스, 시간 등을 포함한다.
라. 위험상황에 대한 정의 및 범위
- 저희 조가 정의한 위험 상황은 '시니어 분들이 집 안에서 혼자 계실 때, 어떠한 이유로 보호자 측에 연락을 취할 수 없는 상황이 되어 빠른 대처가 되지 않았을 때, 시니어 분들의 건강 악화가 우려되는 경우나 목숨의 위험이 있는 경우에 보호자 측에서 인지하지 못하고 있는 경우’이다.
- 그리고 위험상황을 분류할 행동들은 낙상이다. 낙상을 감지하는 기준은 모델을 학습시킬 때 들어간 ETRI-Activity3D 데이터셋의 영상들이 기준이 될 것이다.
이론적 계산 및 시뮬레이션
가. Pose Detection API의 이론적 과정
- Pose Detection API는 BlazePose를 기반으로 작동하는 API이다. BlazePose는 모바일에서도 human pose estimation에 대한 real-time inference가 가능한 모델이다. BlazePose는 heatmap과 regression을 모두 이용해 lightweight pose estimaion을 한다는 장점이 있다.
- 기존의 자세 추정 모델은 heatmap을 이용해 각 관절에 대한 heatmap을 생성해 각 관절 좌표에 대한 offset을 수정하는 방식으로 진행되었지만, single person에 대한 실시간 자세 추론을 하기에는 모델이 너무 크다는 단점이 존재했다.
- Regression 기반 모델은 컴퓨팅 리소스가 저렴하고 확장성이 크나, 관절이 맞물리는 경우에 예측이 취약하다는 단점이 있지만, BlazePose는 인코더 디코더 신경망을 이용해 모든 관절의 heatmap을 예측한 후, 다른 encoder로 regression을 이용해 각 관절의 좌표를 예측하는 구조를 가지고있으며, 추론당시에 heatmap부분을 제외해 모바일에서도 돌릴 수 있을 정도로 가볍게 만들어진다.

- 추론 파이프라인은 lightweight body pose detector와 pose tracker 순서로 구성된다. tracker는 keypoint 좌표, 사람 존재 유무, 현재 프레임의 ROI(Region Of Interesting)를 예측한다. Tracker에서 사람이 없다고 판단할 경우 다음 프레임에서 detector를 재실행한다.
- 최근의 객체 탐지 방법은 대부분 NMS(Non-Maximum Suppression)으로 후처리를 한다. 하지만 NMS는 keypoint가 겹치는 동작에서 오류가 발생한다는 단점이 있다.
- BlazePose에서는 detector의 기준을 명확한 특징이있고, 편차가 적은 얼굴로 정하여, 사람의 골반 중앙값, 사람을 포함하는 원의 크기, 사람의 기울기 등의 alignment parameter를 예측한다.
- BlazePose는 heatmap, offset, regression을 결합한 방식을 이용했다. Heatmap과 offset Loss는 학습과정에서만 이용하고, 추론을 할 때에는, output Layer를 제거해 경량화하여 regression encoder에서 활용할 수 있도록 햇다. 해당 방식은 인코더-디코더 히트맵 기반 신경망 뒤에 regression 신경망이 따라오는 구조를 쌓는 방식으로 적용했다.


나. 1차 판단 알고리즘 이론적 과정 및 시뮬레이션
- 기존에 낙상에 따른 신체 관절의 동적 특성을 분석한 논문[1]에 따르면, 낙상 행동에서 땅에 닿기까지 상체는 약 0.8초, 하체는 약 0.5초의 시간이 걸린다고 분석했다. 하지만 해당 1차 판단 알고리즘에서는 어르신들의 움직임을 고려해서 시간의 폭을 좀 더 늘려 사람이 서 있던 자세에서 1초만에 바닥에 쓰러진 자세로 인식된다면 이를 낙상으로 의심한다. 이 특성과 Pose Detection API의 관절 정보로 그린 바운딩 박스의 비율로 1차적으로 낙상 의심 상황을 검출한다.
- 바운딩 박스
- 스켈레톤으로 낙상을 감지했던 기존 논문[4]을 참고하여 바운딩 박스를 이용하여 1차 판단을 사용하기로 하였다. 하지만 기존 알고리즘과 해당 알고리즘의 차이점은 Pose Detection API 추출한 33개의 정보 중에서 팔과 관련된 관절 정보(팔꿈치, 손목, 손가락)를 제외한 나머지 관절들을 사용하여 바운딩 박스를 그린다는 점이다. 팔을 제외한 이유는 서 있을 때의 자세와 앉아있을 때의 자세를 구별하기 위함이다. 일반적으로 사람이 바닥에 앉을 때는 바운딩 박스가 정사각형 모양이고, 서 있는 경우에는 세로로 긴 직사각형 모양이다. 이런 상황이라면 서 있을 때나 앉아있을 때를 구별할 수 있다. 하지만, 만약 사람이 서 있는 상태로 양팔을 벌린다면, 아래의 설명 그림 1, 2처럼 두 자세의 바운딩 박스는 둘 다 정사각형에 가깝게 그려지기 때문에 바운딩 박스만 보고 서 있거나 앉아있는 것은 구분하는 것은 어렵다. 이외에도 어떤 자세를 취하든 팔은 움직임이 많기 때문에, 팔을 제외하지 않고는 바운딩 박스의 수식 조건을 일반화하는 것은 어려웠기 때문에 바운딩 박스를 그릴 때 양팔은 제외하기로 하였다. 그 결과, 그림 3, 4처럼 사람이 서 있는 상태로 팔로 다른 행동을 하고 있더라도 바운딩 박스가 똑같게 그려지기 때문에 서 있다는 상태를 판단할 수 있게 되었다.

- 이렇게 구한 바운딩 박스의 폭과 높이를 가지고, 바운딩 박스의 비율 R을 계산한다. 일반적으로 서 있거나 앉아서 무언가를 한다면 R < 1, 바닥에 길게 누워있는 상태에서는 R > 1이다.
- 1차 판단 조건문
- 앞선 바운딩 박스 비율로 현재의 자세를 판단하고, 그 자세가 1.0초만에 서 있는 자세에서 누워있는 자세로 변경된다면 이를 낙상 의심 상황으로 판단한다. 그러기 위해서는 일단 일정 시간마다 바운딩 박스의 비율을 계산해야 한다. w(t),h(t)는 각각 현재 시간 t의 바운딩 박스의 폭과 높이이고, R(t)는 현재 시간의 바운딩 박스의 비율이다.

- 현재 시간의 R(t)값과 1.0초전의 바운딩 박스의 비율 R(t-2)값을 사용하여 조건식을 만들면 1.0초만에 서 있던 자세가 누운 자세로 변경되었는지를 판단할 수 있게 된다. 아래의 조건식에서 α, β값은 각각 서 있는 자세를 구분하기 위한 임계값, 쓰러진 자세를 구분하기 위한 임계값이다.

- 임계값을 찾기 위한 시뮬레이션
- 바운딩 박스의 비율로 자세를 구분할 수 있는 적절한 임계값을 구하기 위해서 일상생활에서 일어날 수 있는 자세들을 직접 취하고, 해당 자세의 비율을 분석하였다. 정면이란 카메라를 정면으로 바라봤을 때를 의미하고, 옆은 카메라가 찍는 방향에 수직한 방향을 바라봤을 때를 의미한다.

- 실험한 자세 바운딩 박스의 R(t)값의 범위를 측정한 결과는 다음과 같다.

- 팔을 제외하였기 때문에 일반적으로 다리를 벌리고 서있는 경우를 제외하면 서 있거나 걸어 다닐 때 (1,2,4,5,6,7,8) 0.45이하의 R(t) 값을 가진다. 또한, 쓰러진 자세(13,14,15,16)는 찍히는 각도에 따라 값의 변동이 심했지만 누워있다는 특징으로 인해 w(t)의 값이 h(t)의 값보다 일반적으로 비율이 컸다. 쓰러진 자세 중에서도 w(t)가 가장 짧게 찍히는 각도인 14,15의 경우에도 R(t)값이 대략 1.2보다는 크다는 것을 알 수 있었다. 이 결과를 통해서 서 있는 자세를 구분하는 임계값 α값은 0.45, 쓰러진 자세를 구분하는 임계값 β값은 1.2로 정하였다. β인 1.2를 넘는 자세에는 쓰러지기 자세 외에도 10,12번 등의 자세들이 있지만, 해당 항목들은 서 있다가 다른 중간 동작없이 1.0초만에 취할 수 없는 자세들이다. 임계값을 이렇게 정함으로써, 서 있다가 앉는 경우나 앉아있다가 눕는 경우는 임계값으로 세워진 조건식을 만족하지 못하기 때문에 서 있다가 쓰러지는 경우만 잡을 수 있게 된다.
- 프레임 속도
- 해당 알고리즘에서는 1.0초를 기준으로 자세를 판단한다. 하지만 1.0초 간격으로 촬영한다면 t-1초와 t초 사이(1.0초)인 중간 지점부터 넘어지는 자세가 시작한다면 정확도가 떨어지게 된다. 그렇기 때문에 이 간격을 줄이고자 프레임 속도를 0.5초로 하여, 0.5초마다 자세를 추출하고 대신 1.0초 전의 값을 비교하는 알고리즘에는 영향을 받지 않도록 2 프레임 전의 R(t)값을 사용하는 방법을 사용한다.
- 조건식
- 앞선 내용을 모두 종합하여 1차적으로 낙상 의심 상황을 판단하는 조건식을 다음과 같다.

다. 3D-Pose-Baseline의 이론적 과정

라. ST-GCN의 이론적 과정
- 행동 인식을 하기 위해 사용하는 데이터셋의 modality는 다양하다. RGB 영상, depth 영상, 움직임의 방향이 표현된 optical flow, 그리고 skeleton data가 있다. ST-GCN은 skeleton을 이용한 행동인식 분류 모델이다. skeleton data의 경우 자연스럽게 사람의 관절의 위치를 시간축에 따라 표현되어진다. 이러한 구조의 data로 학습을 진행하기 위해 이전의 방식에서는 한 frame에서의 관절의 위치 값들을 하나의 feature vector로 사용해서 학습을 시켰었다. 이 방식의 경우, 행동인식에서 관절 간의 관계성 또한 매우 중요함에도 불구하고 해당 정보가 학습에 포함되지않는다. 해당 모델은 공간적 관계성을 찾아내기 위해 GCN(Graph Convolutional Neural Network)를 이용한다.

- 개략적인 모델의 개요는 위의 그림과 같다. 동영상으로부터 skeleton을 추출하고, skeleton data를 그래프 형태로 만든다. 각각의 joint들을 노드로 만들고, 각각의 노드가 이어지는 부분(공간, 시간)을 edge로 연결한다. 총 9개의 ST-GCN 모듈을 통해 feature를 추출한 후, Softmax 함수를 이용하여 행동을 분류한다.
- Skeleton Graph Construction

- Graph Convolutional Neural Network

- Sampling function

- Weight function

- Spatial Graph Convolution

상세설계 내용
가. 유즈케이스
- 유즈케이스 다이어그램

- 액터 목록

- 유즈케이스 설명












나. 시스템 설계

- Frontend
- Android Studio를 이용하여 구현한다.
- 회원가입, 로그인, 주요 기능을 위한 화면을 생성하고, User가 발생시키는 이벤트를 받아 Backend단으로 넘긴다.
- Backend
- Firebase가 제공하는 기능들을 이용하여 구현한다.
- 실시간 데이터베이스 기능을 이용하여 User들의 정보를 저장/수정한다.
- 인증 기능을 이용하여 User 인증을 진행한다.
- 스토리지 기능을 이용하여 이미지를 저장/불러오기한다.
- 호스팅 기능을 이용하여 주소API를 가져와 주소검색 액티비티를 제공한다.
- Frontend단에서 온 이벤트를 처리하고 결과값을 형태에 맞춰 반환한다.
- 딥러닝 모델은 서버에서 처리하지 않고 앱 내부에서 처리하여 결과만 Backend로 넘긴다.
- 장점
- 모든 데이터는 Backend에 모이기 때문에 데이터의 구성과 관리 측면에서 유용하다.
- 서버를 따로 만들어서 쓰는 것이 아니라 제공하는 서비스를 통해 쓰기 때문에 유지보수에 좋고 편리성이 뛰어나다.
다. UI 설계
- 화면 목록

- UI Flow


라. DB 설계
- DB 구성도

결과 및 평가
완료 작품의 소개
프로토타입 사진 혹은 작동 장면
가. 프로토타입 사진 (단말기 앱)
- 회원가입 (SENIOR UI 01)

- 로그인 (SENIOR UI 02)

- 보호자 정보 등록 (SENIOR UI 03)

- 서비스 동작 (SENIOR UI 04)

- 서비스 중지 (SENIOR UI 04-02)

- 주소 입력 (SENIOR UI 05)

- 정보 수정 (SENIOR UI 06)

- 백그라운드 서비스 (SENIOR UI 07)

- 스플래시 화면 (SENIOR UI SPLASH)

나. 프로토타입 사진 (보호자 앱)
- 회원가입 (CARE UI 01)

- 로그인 (CARE UI 02)

- 관리 시니어 정보 (CARE UI 03)

- 관리 시니어가 없을 때 (CARE UI 03-02)

- 위험 상황 상단 알림 (CARE UI 04)

- 시니어가 호출 시 상단 알림 (CARE UI 04-02)

- 위험 상황 인지 (CARE UI 05)

- 스플래시 화면 (CARE UI SPLASH)

다. 낙상 감지 알고리즘
- 옆 방향으로 쓰러졌을 때 낙상 감지1

- 1차 판단, 2차 판단을 모두 충족하여 낙상으로 인지
- 옆 방향으로 쓰러졌을 때 낙상 감지2

- 1차 판단, 2차 판단을 모두 충족하여 낙상으로 인지
- 카메라 쪽에 머리를 두고 쓰러졌을 때 낙상 감지

- 1차 판단, 2차 판단을 모두 충족하여 낙상으로 인지
- 카메라 쪽에 발을 두고 쓰러졌을 때 낙상 감지

- 1차 판단, 2차 판단을 모두 충족하여 낙상으로 인지
- 낙상 없이 일상생활1

- 낙상 인지를 하지 않음
- 낙상 없이 일상생활2

- 낙상 인지를 하지 않음
완료작품의 평가
- 평가 기준

- 평가 결과
- 분류 정확도
- 모델 속도
- 응답 시간
- 분류 정확도



- 평과 결과 분석
- 분류 정확도
- 낙상에 대한 상황이 아닌 일상 생활에서도 1차 알고리즘을 통과하는 경우가 있었다. 1차 알고리즘이 통과하는 원인을 보니 인간이 아닌 물건을 인간 객체로 인식하는 경우, 낙상이 아닌 상황이지만 1차 조건식을 통과하는 행동(ex. 다리를 벌리고 몸을 숙이는 행동) 등이 있었다. 하지만 이런 경우에는 1차는 통과하지만 쓰러져있는 상황이 아니기 때문에 2차 판단인 딥러닝 모델을 통과하지 못하여 최종적으로는 낙상으로 판단하지 않았다.
- 낙상에 대한 분류 정확도를 전,후,좌,우 방향으로 나누어 테스트를 진행하였다. 좌,우에 비해서 전,후의 정확도가 더 낮은 것을 확인할 수 있었다. 이는 1차적으로 스켈레톤 구조를 추출하는 Pose Detection API의 한계였다. Pose Detection API는 얼굴로 인간 객체를 찾고, 얼굴을 기반으로 나머지 관절 정보를 추출한다. 하지만 전방, 후방으로 낙상을 하는 경우에는 카메라에 얼굴이 잘 안보이는 경우가 많았고, 이 때문에 아예 관절 정보를 추출하지를 못하였다. 이러한 경우 때문에 전,후방의 정확도가 좌,우에 비해서 낮았다. 좌,우로 넘어지는 경우에는 전,후방에 비해 얼굴이 카메라에 나와 객체를 잘 탐지할 확률이 확실히 높아 낙상을 잘 인지하였지만, 관절 정보를 추출할 수 없을 정도로 얼굴이 보이지 않는 경우가 있어 낙상으로 인지되지 않을 때가 있었다.
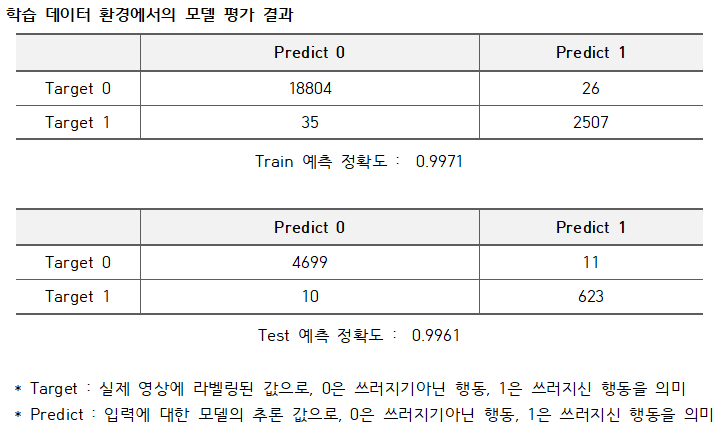
- 딥러닝 모형 기반인 2차 판단의 성능은 train_set과 test_set에서 정확도는 0.9971, 0.9961로 높은 성능을 보였다. 하지만, 이는 잘 구성된 학습 데이터 상에서의 성능이였고, 실제 AI 단말기에서 촬영된 영상을 가지고 여러가지 행동을 취해보며 성능을 측정했다. 기존의 학습 데이터에서 존재했던 47개의 행동 종류 외의 다른 행동을 취했을 경우 모델이 해당 행동을 잘 처리하지 못하는 문제가 존재했다. 학습 데이터가 수집될 때 사용되었던 카메라의 성능, 각도가 현재 AI 단말기에서 사용되는 카메라와 다르다는 점도 성능 하락의 문제로 생각되었다. 실생활에서 예측할 수없는 수많은 행동들을 잘 분류할 수 있도록, 여러가지 행동들이 있는 대규모 영상 데이터셋을 통해 추가적인 학습이 진행되어야할 것이라고 판단되고, 모델의 최적화를 더 진행하여 강건한 시스템을 만들어야된다고 판단된다.

어려웠던 점
- FCM을 이용해 양방향으로 통신 보내기
- 눕기와 낙상을 정확히 판별하기
- 단말기 앱 내부에서 모든 모델이 처리되는 데에 긴 시간 소요
- 모델을 돌리는 동안 사진 데이터를 저장하고 있을 메모리 공간 부족
- 학습데이터 전처리 및 학습에 긴 시간 소요
- 앞, 뒤로 쓰러지는 것에 대한 처리
향후계획
- 학습 데이터를 추가적으로 구성하여 현재 어르신들의 47종류의 일상행동 이외의 행동들도 모델에 학습시키고, 이진 분류 모델을 다중 분류 모델로 구현한다.
- 시니어 여러 명과 보호자 한 명을 연결할 수 있도록 구현한다.
- 위험 상황 전에 나타날 수 있는 전조 증상에 대한 행동 인식을 추가하여 모델을 학습한다.