"제주어디갈래"의 두 판 사이의 차이
cdc wiki
(→개발 과제의 개요) |
(→향후평가) |
||
| (같은 사용자의 중간 판 19개는 보이지 않습니다) | |||
| 100번째 줄: | 100번째 줄: | ||
* 비슷한 예의 프로그램에 대한 특허의 법적상태가 거절인 것을 확인할 수 있었으므로, 특허권 침해에 대한 큰 고민 없이 개발을 진행해도 무리가 없을 것이라고 판단함. | * 비슷한 예의 프로그램에 대한 특허의 법적상태가 거절인 것을 확인할 수 있었으므로, 특허권 침해에 대한 큰 고민 없이 개발을 진행해도 무리가 없을 것이라고 판단함. | ||
| − | === | + | ===관련 시장에 대한 분석=== |
| − | ==== | + | ====경쟁제품 조사 비교==== |
* 대한민국 구석구석 | * 대한민국 구석구석 | ||
:: 주요 기능: 지역별 인기 관광지 및 코스 추천, 축제 정보 제공 | :: 주요 기능: 지역별 인기 관광지 및 코스 추천, 축제 정보 제공 | ||
| 110번째 줄: | 110번째 줄: | ||
* 경기관광포털 | * 경기관광포털 | ||
:: 주요 기능: 카테고리별 여행지 추천, 여행 코스 추천, 축제 정보 제공, 포토갤러리 | :: 주요 기능: 카테고리별 여행지 추천, 여행 코스 추천, 축제 정보 제공, 포토갤러리 | ||
| − | ==== | + | ====마케팅 전략==== |
* 기존의 여행 코스 추천 사이트와는 다르게 여행 계획에 들어가는 시간을 절약할 수 있음을 강조한다. | * 기존의 여행 코스 추천 사이트와는 다르게 여행 계획에 들어가는 시간을 절약할 수 있음을 강조한다. | ||
| − | [[파일: | + | [[파일:w1.png]] |
==설계== | ==설계== | ||
| − | === | + | ===사용자 요구사항=== |
* 선호하는 여행지에 따라 여행지 노트를 추천받을 수 있다. | * 선호하는 여행지에 따라 여행지 노트를 추천받을 수 있다. | ||
* 여행지에 대한 평가 및 정보를 입수할 수 있다. | * 여행지에 대한 평가 및 정보를 입수할 수 있다. | ||
| + | |||
===사용자 요구사항 만족을 위한 기능 정의 및 기능별 정량목표=== | ===사용자 요구사항 만족을 위한 기능 정의 및 기능별 정량목표=== | ||
* 여행지 노트 추천 | * 여행지 노트 추천 | ||
| 127번째 줄: | 128번째 줄: | ||
===개념설계안=== | ===개념설계안=== | ||
* 사용자 인증 | * 사용자 인증 | ||
| − | :: 토큰 기반 사용자 | + | :: JWT는 유저를 인증하기 식별하기 위한 토큰 기반 인증입니다. 세션과는 달리 서버가 아닌 클라이언트에 저장되기 때문에 서버의 부담을 훨씬 덜 수 있습니다. |
| − | * | + | |
| − | :: | + | :: Restful의 경우 무상태성이 큰 특징인데 유저의 인증이라는 ‘상태’를 담아야하기 때문에 패러다임의 충돌이 생기게 됩니다. 따라서 토큰 자체에 사용자 권한 정보나 서비스를 사용하기 위한 정보가 포함되어있습니다. 해당 토큰들은 Redis 상에서 관리되게 되고 access token의 경우 30분, refresh token의 경우 30일의 유효 기간이 존재합니다. access token이 만료되었다면 refresh token을 통해 다시 access token을 재발급받아 서버에 접속 가능합니다. |
| + | |||
| + | :: JWT를 사용하면 클라이언트에서 id, password를 통해 웹서비스 인증을 진행합니다. 해당 id, password가 일치한다면 서버에서 서명된 JWT를 생성해서 클라이언트에게 돌려줍니다. 이후 클라이언트는 인증이 필요한 페이지에 접속할 시 header에 access token을 포함하여 전송하게 됩니다. 그 후 서버는 access token의 유효성을 검사하고 유효하다면 내부 filter에서 걸러지지 않고 접속을 허락하게 됩니다. | ||
| + | |||
| + | * 데이터 전처리 | ||
| + | :: 데이터 크롤링의 경우 네이버 리뷰, 다음 리뷰, trip advisor 3개의 플랫폼에서 리뷰를 가져오려고 하였습니다. Trip advisor, 네이버 리뷰, 다음 리뷰에서 합계 총 53만 개의 리뷰를 추출하였습니다. | ||
| + | ::[[파일:q1.png]] | ||
| + | :: 전처리의 경우 한양대 여행 경로 추천 논문에서 20개 이상의 리뷰를 가진 유저나 POI만 전처리했던 것을 토대로 같은 전처리를 수행하였고 최종적으로 약 8만 개 정도의 리뷰를 사용하였습니다. | ||
| + | ::[[파일:q2.png]] | ||
| + | :: Rating data의 경우 다음과 같은 분포를 가집니다. 별점 5.0점에 굉장히 skew되있는 것을 확인할 수 있습니다. 실제로 예측이 5점으로 많이 분포되었기 때문에 test set의 에러가 0.57점으로 낮게 나오더라도 좋은 모델이라고 보기에는 힘들다고 생각합니다. | ||
| + | |||
* 추천 시스템 개발 | * 추천 시스템 개발 | ||
| − | :: | + | :: 저희는 다음과 같이 3가지의 모델을 고려하였습니다. |
| + | |||
| + | :: Dataset 종류의 경우 explicit dataset과 implicit dataset가 존재합니다. Explicit dataset의 경우 user가 item에 남긴 별점 자체를 회귀 분석을 통해 예측하도록 하는 dataset이고 implicit dataset의 경우 user가 item에 남긴 상호작용을 0 또는 1로 표현하는 dataset으로 binary classification으로 예측이 이루어져야합니다. 저는 두 가지 방법 모두 사용하여 실험하였습니다. | ||
| + | |||
| + | ====Item-based Collaborative Filtering==== | ||
| + | : dataset 종류, 유사도, 예측 방법, 알고리즘 순으로 설명드리겠습니다. | ||
| + | |||
| + | : Dataset 종류의 경우 explicit dataset과 implicit dataset가 존재합니다. Explicit dataset의 경우 user가 item에 남긴 별점 자체를 회귀 분석을 통해 예측하도록 하는 dataset이고 implicit dataset의 경우 user가 item에 남긴 상호작용을 0 또는 1로 표현하는 dataset으로 binary classification으로 예측이 이루어져야합니다. 저는 두 가지 방법 모두 사용하여 실험하였습니다. | ||
| + | |||
| + | : 사용하는 유사도는 cosine 유사도, correlation 유사도, adjusted cosine 유사도를 사용합니다. | ||
| + | :[[파일:q3.png]] | ||
| + | : 먼저, cosine 유사도는 item i, j의 rating vector를 cosine 내적하여 유사도를 구하는 방식입니다. | ||
| + | :[[파일:q4.png]] | ||
| + | : 다음으로 correlation 유사도는 rating 자체를 item rating의 평균을 빼고 분산을 나누어주어 표준화를 거친 후 cosine 유사도를 측정하는 방식입니다. | ||
| + | :[[파일:q5.png]] | ||
| + | : 마지막으로 adjusted cosine 유사도의 경우는 correlation 유사도에서 평균과 분산을 item rating 대신 user rating을 사용한 것입니다. 즉, user의 별점을 주는 성향까지 추가로 고려한 방식으로 해당 논문에서는 adjusted cosine 유사도 방식이 제일 좋은 결과가 나왔습니다. | ||
| + | |||
| + | : 예측 방법입니다. Weighted sum 방식과 regression이 존재합니다. | ||
| + | :[[파일:q6.png]] | ||
| + | : Weighted sum의 경우 유사도(0~1 사이로 표시됨)와 rating을 곱하여 유사도가 높은 item의 rating이 더 많이 반영되도록 한 예측 방법입니다. | ||
| + | :[[파일:q7.png]] | ||
| + | : Regression의 경우 weightecd sum과 동일한 산식을 쓰지만 2 개의 item vector가 유클리드 거리는 멀지만 유사도가 높게 나오는 경우 때문에 예측 정확도가 떨어질 수 있음을 고려한 방법이라고 논문에 등장합니다. | ||
| + | |||
| + | : 최종적으로 적용했던 알고리즘 로직을 설명드리겠습니다. | ||
| + | |||
| + | : PlaceReview 테이블에 저장되어있는 리뷰 데이터를 전부 불러와서 user, place 각각 리뷰가 20개 이상인 것만 추출하여 전처리합니다. 그 후 별점이 없는 부분은 0점으로 만들어 explicit dataset matrix를 구성합니다. 이 때, target으로 하는 user가 방문하지 않았던 place와 방문한 Place를 구분하여 추출합니다. 그 후, 방문하지 않은 장소와 방문했던 장소들과의 item similarity 값을 3가지 유사도 방법 중 하나를 사용하여 추출합니다. 그 다음 해당 유사도와 가본 장소의 rate를 weighted sum 방식으로 합산하여 최종 예측 별점을 추출합니다. 마지막으로 안 가본 장소들의 예측 rating을 내림차순 정렬하여 추천 받을 장소 개수대로 유저에게 top N개를 제공합니다. | ||
| + | |||
| + | ====Neural Collaborative Filtering==== | ||
| + | : 해당 알고리즘은 기존 Matrix Factorization의 한계점으로부터 제안되었습니다. 기존 Matrix Factorization의 한계점은 user와 item 간의 복잡한 관계를 표현하는데 한계가 있음을 지적하였습니다. | ||
| + | :[[파일:q8.png]] | ||
| + | : Sij는 user i와 j의 유사도를 나타낸다고 가정합니다. 그 때, user 2와 3이 가장 비슷하고 user 1과 3이 가장 덜 비슷하다는 결과가 나옵니다. 하지만 새로운 user 4가 들어올 때 4와 1이 가장 비슷하고 4와 2가 가장 비슷하지 않게 유사도가 나오게 됩니다. 그렇게 되면 p1과 가까운 동시에 p2를 가장 멀리하는 p4 벡터를 찾을 수 없습니다. 즉, user와 item을 저차원에 단순한 공간에서 표현하는데에 있기 때문에 neural network 구조를 추가하여 관계에 복잡성을 더하는 것입니다. | ||
| + | |||
| + | : 모델 구조는 user one-hot vector를 embedding layer에 mapping하여 user latent vector를 만들고, item one-hot vector를 embedding layer에 mapping하여 item latent vector를 생성합니다. 해당 2개의 vector를 concatenate한 것을 DNN 구조에 통과시켜 기존 gradient descent 방식으로 학습하는 것이 목표입니다. 이 때, 예측하는 지표의 경우 0 또는 1의 binary 값인데 그 이유는 해당 알고리즘에서 별점을 직접적으로 활용하는 explicit dataset보다 유저와 item의 상호작용을 0 또는 1로 표시하는 Implicit dataset 방법을 골랐기 때문입니다. 논문에서는 해당 알고리즘에 implicit dataset이 효과가 좋다고 나와있습니다. | ||
| + | |||
| + | : 최종적인 NeuMF 구조의 경우에는 위에서 설명했던 MLP 구조에 Matrix Factorization을 추가로 수행하는 GMF Layer를 추가하여 최종 예측을 수행합니다. 최종 모델 구조는 다음과 같습니다. | ||
| + | :[[파일:q9.png]] | ||
| + | |||
| + | ====최종 사용한 모델==== | ||
| + | : Neural Collaborative Filtering, Youtube DNN의 경우 논문의 요점 파악과 코드로의 재현이 어려웠던 점, Backend 개발과 AI 모델 개발을 병행하다보니 발생하는 시간적인 문제 때문에 구현에 실패하였습니다. 따라서 Item-based Collborative Filtering에서 유사도 측정, dataset 종류, 예측 계산에 있어서 모든 조합을 고려하여 최종적으로 Mean Average Error를 계산하였을 때 Correlation based similarity, weighted sum, explicit dataset을 사용하였을 때 0.57점 정도의 평균 에러가 발생하였고 해당 에러가 최선의 결과였습니다. 한양대 논문 상에서는 1.2점의 MAE 에러가 나왔는데 더 좋은 결과가 나왔다고 볼 수 있습니다. 하지만, 예측 자체가 skew된 5.0점을 주로 예측하여서 측정 에러 값이 낮은 편이어도 적절한 예측이 이루어졌다고 보긴 어렵다고 판단하였고 저희 프로젝트에 다양한 모델 적용을 못한 것이 아쉽습니다. | ||
| + | |||
* DB 설계 | * DB 설계 | ||
| − | + | :[[파일:q10.png]] | |
| + | : 설계한 erd입니다. Erdcloud를 통해 테이블을 생성하였습니다. 모든 table에는 PK인 id와 row가 생성된 날짜를 표시하는 createdAt column, 업데이트된 날짜를 표시하는 updatedAt column이 공통적으로 존재합니다. | ||
| + | |||
| + | : 먼저, user table입니다. User와 관련된 인적사항 및 인증 관련 column을 저장합니다. Img의 경우 user profile picture가 들어가게 되는데 s3에 user 프로필 이미지를 저장하고 해당 s3의 이미지 링크를 img column에 저장합니다. 이후 프론트엔드에서 해당 링크에 해당되는 이미지를 띄워주게 됩니다. Password의 경우 내부에서 원래 password를 다른 문자열로 encoding하는 방식으로 저장하여 password를 DB 상에서 확인할 수 없게 하였습니다. | ||
| + | |||
| + | : 두번째로, note table입니다. Note라는 것은 유저의 여행 노트를 말하는 것인데 유저 한 명이 여러 개의 노트를 생성할 수 있는 1:n 관계입니다. Adult, Animal, Child는 각각 여행가는 성인, 애완동물, 아이 수를 뜻하며 day_end, day_start의 경우 여행 시작 날짜와 종료 날짜 각각을 저장합니다. Public share의 경우에는 해당 여행 노트를 다른 사람들에게 공유할지 여부를 뜻하며 thumbnail은 여행 노트의 썸네일 이미지 s3 링크, title은 노트 제목, max_place_per_day는 하루 당 몇 개의 관광지를 추천받을지 저장합니다. 해당 column 정보들을 통해 flask 내부에서 여행 일수를 계산하고 max_place_per_day를 통해 총 추천받을 관광지 개수를 계산해서 추천 시스템 로직을 통해 유저에게 제공합니다. 추가로 옆에 NotePlace 테이블의 경우에는 유저에게 최종 추천해준 장소를 저장하는 table입니다. | ||
| + | |||
| + | : 세 번째로 Place입니다. 장소의 이름, 전화번호, 주소, 여행지 태그가 기본적으로 저장됩니다. Point라는 column은 Spring 내부적으로 Point라는 클래스로 위도 경도를 저장합니다. 프론트엔드가 해당 point column 값을 받아 카카오 api 상에 장소 위치를 표시합니다. likeCount같은 경우에는 장소에 좋아요가 몇 개인지 저장하는 역할을 합니다. PlaceLike에서 해당 Place 관련 row가 몇 개인지 세는 방법으로 좋아요를 구하는 방법도 있지만 Join 연산으로 인해 조회가 오래걸리는 것을 고려해서 파생 column을 만들어 부하를 줄여주는 방법을 택한 것입니다. | ||
| + | |||
| + | : 마지막으로 User와 Place 사이에 m:n 형식으로 여러 table들이 존재합니다. User가 Place에 남길 수 있는 좋아요가 PlaceLike 테이블로, 댓글이 PlaceComment 테이블로, 리뷰가 PlaceReview 테이블로 나타납니다. PlaceReview 테이블의 경우 별점과 내용이 저장되는데 이전에 크롤링했던 데이터 53만 개의 데이터가 해당 table로 import됩니다. Survey의 경우 유저가 회원가입 시 기본으로 20개의 랜덤 place에 대한 rating을 매길 수 있도록 하였습니다. Survey가 작성되면 내부 비즈니스 로직에서 자동으로 PlaceReview 테이블에도 row로 추가됩니다. | ||
| + | |||
* 최종 아키텍처 | * 최종 아키텍처 | ||
| − | [[파일: | + | :[[파일:w2.png]] |
| + | : Vercel로 frontend 배포를 하고 frontend에서 도메인 주소에 접속하면 route 53에서 해당 도메인에 해당되는 ec2로 안내를 도와줍니다. 백엔드 부분의 경우 code deploy와 s3를 사용해서 ec2 상에 코드를 배포하게 되고 docker 환경을 사용하여 배포를 하게 됩니다. 도커 환경에는 nginx, spring, redis, flask가 존재합니다. Nginx를 사용한 이유는 정적 페이지의 경우 web application server인 spring이 처리하지 않고 대신 페이지를 return해주어 부하를 줄여주기도 하고 하나의 스레드가 여러 요청을 처리하기 때문에 많은 트래픽에 상당한 강점을 가지고 있습니다. spring은 web application server로서 전체적인 DB crud를 맡는 즉, 동적인 웹 요청을 맡는 비즈니스 로직을 실행합니다. Flask의 경우는 추천 시스템 알고리즘 자체를 python으로 작성하였기 때문에 flask로 요청을 받는 것이 유리할 것이라고 판단하여 사용하였습니다. Spring에서 추천 관련 요청을 flask로 보내면 flask가 추천 경로를 응답하여 돌려줍니다. redis의 경우는 cache의 장점도 있고 redis 상에서 토큰 유효기간이 지나면 자동으로 삭제해주는 시스템을 활용하는 장점이 있습니다. Cache의 경우 로그인 요청이 온 유저에 대해 60초 정도 cache를 유지합니다. 또한, 관계 DB에서 토큰을 관리하면 일일이 관계 설정을 해야되는 번거로움이 있기에 nosql인 redis를 사용하였습니다. DB의 경우 rds 관계 DB를 활용하고 ec2와 rds를 같은 VPN 상에 두어 서로 통신이 가능하게 합니다. | ||
| + | |||
| + | : 추가로 github actions와 aws code deploy를 같이 사용하여 continuous deployment를 구현하였고 코드를 push할 시 자동으로 ec2 내부에 배포되도록 하였습니다. | ||
===유스케이스 다이어그램=== | ===유스케이스 다이어그램=== | ||
| − | ==== | + | ====액터 목록==== |
| − | [[파일: | + | [[파일:w3.png]] |
| − | [[파일: | + | ====유스케이스 설명==== |
| − | + | [[파일:w5.png]] | |
| − | [[파일: | + | |
| − | [[파일: | + | [[파일:w4.png]] |
| − | [[파일: | + | |
| − | [[파일: | + | [[파일:w6.png]] |
| − | [[파일: | + | |
| + | [[파일:w7.png]] | ||
| + | |||
| + | [[파일:w8.png]] | ||
| + | |||
| + | [[파일:w9.png]] | ||
| + | |||
| + | [[파일:w10.png]] | ||
==결과 및 평가== | ==결과 및 평가== | ||
===완료 작품의 소개=== | ===완료 작품의 소개=== | ||
| − | ==== | + | ====프로토타입==== |
| − | [[파일: | + | [[파일:e1.png]] |
* 대표 기능 화면입니다. 설문조사 완료 후 사용자 맞춤 여행 계획을 짤 수 있습니다. | * 대표 기능 화면입니다. 설문조사 완료 후 사용자 맞춤 여행 계획을 짤 수 있습니다. | ||
===실행=== | ===실행=== | ||
| − | ==== | + | ====SW 실행 방법==== |
| − | [[파일: | + | [[파일:e2.png]] |
* 사이트 접속 후 로그인 화면입니다. | * 사이트 접속 후 로그인 화면입니다. | ||
:: 이메일과 비밀번호에 정규표현식을 삽입해 이메일과 비밀번호 양식이 모두 맞을 때 로그인 버튼이 활성화되도록 구현했습니다. | :: 이메일과 비밀번호에 정규표현식을 삽입해 이메일과 비밀번호 양식이 모두 맞을 때 로그인 버튼이 활성화되도록 구현했습니다. | ||
| − | [[파일: | + | [[파일:e3.png]] |
* 회원가입 화면입니다. | * 회원가입 화면입니다. | ||
:: 이메일, 비밀번호, 닉네임, 핸드폰 번호, 이름, 거주 지역을 정보로 입력받고 있고 필수정보가 모두 입력되어야 회원가입 버튼이 활성화되도록 구현했습니다. | :: 이메일, 비밀번호, 닉네임, 핸드폰 번호, 이름, 거주 지역을 정보로 입력받고 있고 필수정보가 모두 입력되어야 회원가입 버튼이 활성화되도록 구현했습니다. | ||
| − | [[파일: | + | [[파일:e4.png]] |
* 로그인 후 이용자의 여행지 성향을 분석하기 위한 설문조사 시작 화면입니다. | * 로그인 후 이용자의 여행지 성향을 분석하기 위한 설문조사 시작 화면입니다. | ||
| − | [[파일: | + | [[파일:e5.png]] |
* 설문조사 화면의 예시입니다. | * 설문조사 화면의 예시입니다. | ||
:: 설문조사 상단에 상태 바를 구현하여 사용자가 몇 번째 설문을 하고 있는지 실시간으로 확인할 수 있고 점수를 매길 수 있는 간단한 별표 UI를 라이브러리를 사용해 구현했습니다. | :: 설문조사 상단에 상태 바를 구현하여 사용자가 몇 번째 설문을 하고 있는지 실시간으로 확인할 수 있고 점수를 매길 수 있는 간단한 별표 UI를 라이브러리를 사용해 구현했습니다. | ||
| − | [[파일: | + | [[파일:e6.png]] |
* 설문조사 완료 후 화면입니다. | * 설문조사 완료 후 화면입니다. | ||
| − | [[파일: | + | [[파일:e7.png]] |
* 설문조사 완료 후 사용자 맞춤 여행 계획을 짜기 위한 시작페이지입니다. | * 설문조사 완료 후 사용자 맞춤 여행 계획을 짜기 위한 시작페이지입니다. | ||
:: 여행 일정, 여행 제목, 여행 인원, 외부 공유 버튼, 여행지 개수를 필수 값으로 입력 받고 있고 외부 공유와 여행지 개수는 default 값이 설정되어 있습니다. 필수 값들이 모두 입력되어야 여행지 완성 버튼이 활성화됩니다. 꼭 추가해야할 여행지에는 사용자가 여행을 하면서 꼭 방문하고 싶은 여행지를 추가할 수 있습니다. 여행지에 검색어를 입력하면 백엔드 서버로 api를 호출해 리스트를 가져옵니다. 이 때 디바운스를 적용해서 불필요한 api 호출을 방지했습니다. | :: 여행 일정, 여행 제목, 여행 인원, 외부 공유 버튼, 여행지 개수를 필수 값으로 입력 받고 있고 외부 공유와 여행지 개수는 default 값이 설정되어 있습니다. 필수 값들이 모두 입력되어야 여행지 완성 버튼이 활성화됩니다. 꼭 추가해야할 여행지에는 사용자가 여행을 하면서 꼭 방문하고 싶은 여행지를 추가할 수 있습니다. 여행지에 검색어를 입력하면 백엔드 서버로 api를 호출해 리스트를 가져옵니다. 이 때 디바운스를 적용해서 불필요한 api 호출을 방지했습니다. | ||
| − | [[파일: | + | [[파일:e8.png]] |
* 사용자 맞춤형 여행 코스 페이지입니다. | * 사용자 맞춤형 여행 코스 페이지입니다. | ||
:: 사용자가 입력한 정보를 바탕으로 사용자 취향에 맞게 여행지를 추천해주는 페이지입니다. 여행지 추천 기능뿐만 아니라 링크 공유, 동선 최적화, 동행자 추가, 비슷한 성향의 여행자가 만족한 여행지 추천, 숙소 추천, 맛집 추천, 항공권 예매, 네이버 길찾기 리다이렉션, 여행지 순서 변경과 같은 기능들을 제공합니다. | :: 사용자가 입력한 정보를 바탕으로 사용자 취향에 맞게 여행지를 추천해주는 페이지입니다. 여행지 추천 기능뿐만 아니라 링크 공유, 동선 최적화, 동행자 추가, 비슷한 성향의 여행자가 만족한 여행지 추천, 숙소 추천, 맛집 추천, 항공권 예매, 네이버 길찾기 리다이렉션, 여행지 순서 변경과 같은 기능들을 제공합니다. | ||
| − | [[파일: | + | [[파일:e9.png]] |
* 여행지의 상세 정보를 보여주는 페이지입니다. | * 여행지의 상세 정보를 보여주는 페이지입니다. | ||
:: 여행지마다의 상세 정보를 보여줍니다. 반려동물이 입장가능한지 아이들을 위한 여행지인지 운영시간, 입장료, 상세 설명과 같은 정보가 있고 구글 번역 api를 사용해 영문으로도 정보를 받아볼 수 있습니다. | :: 여행지마다의 상세 정보를 보여줍니다. 반려동물이 입장가능한지 아이들을 위한 여행지인지 운영시간, 입장료, 상세 설명과 같은 정보가 있고 구글 번역 api를 사용해 영문으로도 정보를 받아볼 수 있습니다. | ||
| 188번째 줄: | 258번째 줄: | ||
===성과물=== | ===성과물=== | ||
====포스터==== | ====포스터==== | ||
| − | ==== | + | ====대외전시 포스터==== |
| − | [[파일: | + | [[파일:e10.png]] |
* 여행객들이 관심을 가질만한 디자인으로 사이트 로고를 준비했습니다. | * 여행객들이 관심을 가질만한 디자인으로 사이트 로고를 준비했습니다. | ||
* 여행이라는 테마를 한눈에 알 수 있게 비행기와 캐리어 그림을 사용해 아이콘을 만들었습니다. | * 여행이라는 테마를 한눈에 알 수 있게 비행기와 캐리어 그림을 사용해 아이콘을 만들었습니다. | ||
| 195번째 줄: | 265번째 줄: | ||
===완료작품의 평가=== | ===완료작품의 평가=== | ||
| − | [[파일: | + | [[파일:r1.png]] |
| − | [[파일: | + | [[파일:r2.png]] |
===향후평가=== | ===향후평가=== | ||
| − | ==== | + | ====어려웠던 내용들==== |
* 네이버와 카카오 두 플랫폼에서 상당한 양의 여행지 데이터를 수집하였으나, 리뷰가 적은 데이터가 많아 전처리 후 쓸만한 데이터가 많이 남지 않았다. 또한, 어떤 정보를 추천 시스템에 사용할지 정하는 데에 대한 어려움이 있었다. | * 네이버와 카카오 두 플랫폼에서 상당한 양의 여행지 데이터를 수집하였으나, 리뷰가 적은 데이터가 많아 전처리 후 쓸만한 데이터가 많이 남지 않았다. 또한, 어떤 정보를 추천 시스템에 사용할지 정하는 데에 대한 어려움이 있었다. | ||
* 확도가 높은 추천 시스템을 위해 어떤 알고리즘을 적용시켜야 하는지 정하기 어려웠다. | * 확도가 높은 추천 시스템을 위해 어떤 알고리즘을 적용시켜야 하는지 정하기 어려웠다. | ||
* 깔끔하면서도 직관적인 웹 디자인을 고심하여여 제주를 상징하는 오렌지색을 테마로 하였다. | * 깔끔하면서도 직관적인 웹 디자인을 고심하여여 제주를 상징하는 오렌지색을 테마로 하였다. | ||
| − | ==== | + | ====차후 구현할 내용==== |
* 리뷰 수가 적어 사용하지 못했던 장소 데이터의 정보를 찾아 추천 여행지 늘리기 | * 리뷰 수가 적어 사용하지 못했던 장소 데이터의 정보를 찾아 추천 여행지 늘리기 | ||
* 게시판이나 포토갤러리 등을 구현해 이용자 간 정보 공유 활성화를 유도 | * 게시판이나 포토갤러리 등을 구현해 이용자 간 정보 공유 활성화를 유도 | ||
* 사용했던 추천 알고리즘이 적절한지를 확인하고 더욱 최적화시키기 | * 사용했던 추천 알고리즘이 적절한지를 확인하고 더욱 최적화시키기 | ||
* 더욱 깔끔한 이용자 경험을 위해 디자인 다듬기 | * 더욱 깔끔한 이용자 경험을 위해 디자인 다듬기 | ||
| − | |||
==개발 사업비 정산== | ==개발 사업비 정산== | ||
| 221번째 줄: | 290번째 줄: | ||
===관련사업비 내역서=== | ===관련사업비 내역서=== | ||
| − | [[파일: | + | [[파일:r3.png]] |
==부록== | ==부록== | ||
2022년 12월 20일 (화) 08:09 기준 최신판
프로젝트 개요
기술개발 과제
국문 : 제주어디갈래
영문 : jejuwhere
과제 팀명
제주어디갈래
지도교수
황*수 교수님
개발기간
2022년 9월 ~ 2022년 12월 (총 4개월)
구성원 소개
서울시립대학교 컴퓨터과학부 20179200** 이*준(팀장)
서울시립대학교 컴퓨터과학부 20179200** 원*인
서울시립대학교 컴퓨터과학부 20179200** 윤*준
서울시립대학교 컴퓨터과학부 20179200** 이*기
서론
개발 과제의 개요
개발 과제 요약
- 제주도에 관한 여행지 정보를 토대로 사용자 기호에 맞춘 여행지 추천이 주요한 기능
- 제주도 관광지 검색 기능이나 관련 게시물을 보여주는 부가 기능 존재
- 사용자가 클릭한 게시물 혹은 작성한 검사지 결과를 로그로 저장
- 해당 로그를 토대로 recommendation system과 결합하여 취향에 맞는 관광지 추천
- rating만 다루는 기존 recommendation system을 수정하여 다양한 변수를 적용해야함
개발 과제의 배경 및 효과
- 배경/필요성
- 관광지가 다양한 만큼 여행 계획을 짜는 데에 있어 선택 폭이 넓어서 어려움이 존재
- 기존에는 블로그의 제주도 여행 일지에 기록된 남의 취향이 반영된 여행 계획을 따라 하거나 일부분 차용, 혹은 제주도 관광지 등을 검색해가며 그 중 본인 취향인 관광지들을 일일이 선별해야하는 작업을 거쳐야함. 그 과정에서 관광지들끼리의 위치도 비교해야하고 숙소의 위치도 신경써야하기 때문에 여행 계획을 짜는 것이 꽤 까다로움
- 일일이 사용자가 자신이 원하는 곳을 검색하여 리뷰를 확인하고 후보를 추려 목적지를 결정하는 것 은 시간이 꽤 오래걸림, 즉 사용자가 원하는 취향의 관광지를 선별하는 것이 기존에는 사용자에게만 달려있음
- 기술적 개선방안
- 사용자들의 리뷰 정보를 api만으로 얻기에는 한계가 있기 때문에 직접 data 크롤링 library들을 사용하여 부족한 데이터 보완
- rating만 사용하던 기존 추천 시스템에서 유저별 기호를 활용한 측정 지표를 추가하거나 장소의 인기도 등 여러 요인들을 고려하여 알고리즘을 만들고 각각의 성능 비교(Fscore, Recall, Accuracy)를 통해 가장 성능이 좋은 추천 시스템을 사용할 계획
- 효과
- 과제에서 구성한 추천 시스템을 토대로 유저 본인 취향에 맞는 관광지를 스스로 찾기 보다는 사이트 내부 예측 메카니즘이 유저의 그간 취향을 반영하여 제안해주기 때문에 여행 계획을 짜는 데의 과도한 시간 소모나 검색의 번거로움을 없애줄 것임
개발 과제의 목표 및 내용
- 이번 프로젝트의 최종 목표는 사용자에게 거리/별점/기호를 토대로 추천 시스템을 구성하여 DB 내부에 저장된 최적의 목적지를 추천해주고 그를 토대로 지도 api를 활용하여 전체적인 여행 경로를 구성해주는 것
- 사용자는 처음에 당일 여행, 1박 2일, 2박 3일 등 여행 기간을 입력할 수 있음
- 사용자가 추천 알고리즘에 따라 여행 루트를 전부 고르면 최종 소요 거리 및 방문 목적지 정보들을 한 눈에 확인 가능하도록 제공
- 사용자의 기호같은 경우에는 내부 검색 시스템을 사용하여 남긴 검색/클릭 로그나 ‘관광지 취향 검사지’같은 기능을 추가 생성하여 해당 취향을 반영할 것
- 부가 기능으로 관광지 정보를 저장한 DB, 검색 엔진 api를 사용해서 사용자에게 카테고리로 장소 검색, 인기별 장소 나열, 관광지 관련 게시물 검색 기능을 제공할 예정
개발 과제의 기술적 기대효과
- 사용자에게 거리/별점/기호를 토대로 추천시스템을 구성하여 DB 내부에 저장된 최적의 목적지를 추천하고, 지도 api를 활용하여 전체적인 여행 경로를 구성한다.
- 사용자가 추천 알고리즘에 따라 여행 루트를 전부 고르면 최종 소요 거리 및 방문 목적지 정보들을 한 눈에 파악할 수 있다.
- 사용자의 검색/클릭 로그나 ‘관광지 취향 검사지’같은 기능을 통해 사용자의 기호를 파악할 수 있다.
- 관광지 정보를 저장한 DB, 검색엔진 api를 사용하여 사용자에게 카테고리별 장소 검색, 인기별 장소 나열 등의 기능을 제공할 수 있다.
개발 과제의 기술적 기대효과
- 여행 계획 단계의 어려움을 덜어줌으로써 여행 계획 시간을 단축할 수 있다.
관련 기술의 현황
State of art
- 스프링부트(Spring boot)
- 스프링부트는 자바의 웹 프레임워크로 기존 스프링 프레임워크에 톰캣 서버를 내장하고 여러 편의 기능들을 추가하여 꾸준한 인기를 누리고 있는 프레임워크
- 크롤링(Crawling)
- 크롤링이란 인터넷에서 데이터를 검색하여 필요한 정보를 가져오는 것을 의미한다. 웹 서비스 사용자가 키워드를 하나씩 검색해보면서 관련 리포트를 찾는 것이 아닌 미리 정보를 얻어 저장하고 가공하는 것이다. 인터넷 상의 웹페이지를 수집해서 분류하고 저장하여 데이터가 어디에 저장되어 있는지 위치에 대한 분류 작업을 하고 원하는 형태로 가공하는 작업이 주 목적이다.
- NextJS
- Vercel이 개발한 오픈 소스 react SSR 프레임워크로 서비스를 구축하는 데 필요한 최소한의 설정만을 요구하며 컴파일링, 번들링 등 코드가 실제로 만들어지는 과정은 내부적으로 처리한다. Vercel의 목표 중 하나가 'Fast Web'이라는 데서도 알 수 있듯이, 기본적으로 속도를 중시한다. SSR구조 자체로 인한 렌더링 성능과는 별개로 SWC등의 컴파일러를 차용하여 꾸준히 빌드 속도를 올리고 있다.
- Docker
- 운영체제를 가상화하지 않는 컨테이너 기술인만큼 가상머신에 비해서 가벼우며, VM을 포함하여 한 대의 서버에 여러 개의 서비스를 구동하기 좋다. 보안상, 서비스가 털리더라도 원래의 서버에 영향을 미치기가 쉽지 않은 격리된 구조이므로 가상화의 장점을 상당 부분 활용할 수 있다. 구글, 아마존, 마이크로소프트에서도 도커를 지원하고 있다. 그렇기에 가장 큰 장점으로는 사실상 업계 표준이니만큼 사용자들이 작성해둔 소프트웨어 패키지/이미지들이 넘쳐나고 있어서 접근성과 사용하기 좋다는 장점이 있으며 최근에는 클라우드 컴퓨팅에 대해 교육을 진행하는 여러 교육기관에서도 도커에 대한 커리큘럼을 추가하는 경우가 많아지고 있다.
- Nginx
- 무료 오픈 소스 웹서버이고 모든 목적이 높은 성능에 맞춰져 있다. 잘 사용하지 않는 기능은 과감하게 제외를 하였고, 처음부터 트래픽이 방대한 웹사이트 서비스를 위해 설계되었다. 또한 미리 설정된 개수의 worker 프로세스로 운영되고 각각의 프로세스는 싱글 스레드로 동작하여 아파치에 비해 CPU, 메모리 등 자원 사용률이 현격하게 낮은 이점이 있어 차세대 웹서버로 적합하다.
- Redis
- Redis는 오픈 소스로서 NoSQL로 분류되기도 하고, Memcached와 같이 인 메모리 솔루션으로 분류되기도 한다. 성능은 Memcached에 버금가면서 다양한 데이터 구조체를 지원함으로써 DB, Cache, Message Queue, Shared Memory 용도로 사용될 수 있다. 한편, Redis는 Remote Dictionary Server의 약자로 외부에서 사용 가능한 Key-Value 쌍의 해시 맵 형태의 서버라고 생각할 수 있다. 그래서 별도의 쿼리 없이 Key를 통해 빠르게 결과를 가져올 수 있다.
- AWS
- AWS Support 기술 및 프로그램은 환경을 관리 및 모니터링하여 성능과 비용 최적화를 보장하고 보안 및 가동 중단 위험을 관리하며 가능한 범위까지 문제 해결을 자동화하는 데 도움을 준다. 다양한 도구를 이용하여 경고와 알림에 대한 대응을 자동화하고 자체적으로 사용하는 기타 관리 시스템과 통합함으로써 시간을 절약할 수 있다.
- Flask
- restAPI, CORS, DB 연동, MVC, Layerd 패턴 등 기본적인 기술들을 정해진 틀이 아닌 자유롭게 기술을 사용해서 다룰 수 있으며, 그것을 이용해 다른 언어와 프레임워크에 적용이 가능하다. Micro framework로 플스택 프레임워크와는 다르게 필요한 요소를 개발자가 직접 개발하면서 필요한 라이브러리와 패키치를 설치하여 개발할 수 있다.
- Tensorflow
- 텐서플로우는 수치 계산과 대규모 머신러닝을 위한 오픈소스 라이브러리다. 텐서플로우는 다수의 머신러닝과 딥 러닝(신경망) 모델과 알고리즘을 결합해 공통 메타포를 통해 유용성을 높혔다. 파이썬을 사용, 프레임워크로 애플리케이션을 구축하기 위한 편리한 프론트 엔드 API를 제공하며 성능이 우수한 C++로 애플리케이션을 실행한다. 텐서플로우는 필기 숫자 판별, 이미지 인식, 단어 임베딩, 반복 신경망, 기계 번역을 위한 시퀀스 투 시퀀스 모델, 자연어 처리, PDE(편미분방정식) 기반 시뮬레이션 등을 위한 신경망을 학습, 실행할 수 있다.
기술 로드맵
- 로그인, 회원가입, 비밀번호 찾기, 관광지 검색, 리뷰 보여주기, 여행 경로 구성, 댓글 및 좋아요 입력 및 검색, 코스 저장 및 조회 등의 기능 구현
- NextJS를 이용하여 프론트엔드 구현
- 스프링부트를 이용하여 백엔드를 구현
- aihub, 비짓제주, 네이버 리뷰를 크롤링하여 데이터 생성
- mysql로 DB 관리
특허조사
- 공개번호/일자 - 1020170014464 (2017.02.08), 출원인 - 주식회사 케이티, 법적상태 - 거절
- 본 발명은 여행 일정의 추천 방법, 장치 및 컴퓨터 프로그램에 관한 것으로서, 보다 구체적으로는 사용자가 생성하거나 사용한 동영상, 사진, 음악 등의 특성을 분석하여 사용자의 성향을 파악한 후, 상기 사용자의 여행 목적지 및 여행 기간과 상기 사용자의 성향을 고려하여, 상기 사용자에게 적합한 방문 장소 및 스케줄 등 여행 일정을 추천할 수 있는 사용자 성향을 고려한 여행 일정 추천 방법, 장치 및 컴퓨터 프로그램에 관한 것이다. 본 발명은 여행 일정의 추천 방법, 장치 및 컴퓨터 프로그램에 관한 것으로서, 보다 구체적으로는 사용자가 생성하거나 사용한 동영상, 사진, 음악 등의 특성을 분석하여 사용자의 성향을 파악한 후, 상기 사용자의 여행 목적지 및 여행 기간과 상기 사용자의 성향을 고려하여, 상기 사용자에게 적합한 방문 장소 및 스케줄 등 여행 일정을 추천할 수 있는 사용자 성향을 고려한 여행 일정 추천 방법, 장치 및 컴퓨터 프로그램에 관한 것이다.
- 본 발명은 주어진 사용자의 여행 목적지에 대하여, 서버가 상기 사용자에게 방문 장소를 포함하는 여행 일정을 추천하는 방법으로서, 상기 서버가, 상기 사용자가 생성하거나 사용한 컨텐츠 또는 그에 대한 정보를 이용하여 상기 사용자의 성향에 대한 하나 이상의 사용자 키워드를 산출하는 사용자 키워드 산출 단계; 상기 여행 목적지 내에 위치하는 여행 장소들에 대한 특성을 나타내는 여행 장소 키워드와 상기 사용자의 성향에 대한 사용자 키워드를 대비하여, 상기 사용자에게 추천할 방문 장소를 산출하는 방문 장소 산출 단계; 및 상기 서버가 상기 사용자의 단말로 상기 방문 장소를 포함하는 여행 일정을 전달하여 상기 사용자에게 제시하도록 하는 여행 일정 제시 단계를 포함하는 것을 특징으로 하는 여행 일정 추천 방법을 개시하는 효과를 갖는다.
특허전략
- 비슷한 예의 프로그램에 대한 특허의 법적상태가 거절인 것을 확인할 수 있었으므로, 특허권 침해에 대한 큰 고민 없이 개발을 진행해도 무리가 없을 것이라고 판단함.
관련 시장에 대한 분석
경쟁제품 조사 비교
- 대한민국 구석구석
- 주요 기능: 지역별 인기 관광지 및 코스 추천, 축제 정보 제공
- 비지트 서울
- 주요 기능: 카테고리별/지역별 여행지 정보 제공, 교통 정보 제공
- 경기관광포털
- 주요 기능: 카테고리별 여행지 추천, 여행 코스 추천, 축제 정보 제공, 포토갤러리
마케팅 전략
- 기존의 여행 코스 추천 사이트와는 다르게 여행 계획에 들어가는 시간을 절약할 수 있음을 강조한다.

설계
사용자 요구사항
- 선호하는 여행지에 따라 여행지 노트를 추천받을 수 있다.
- 여행지에 대한 평가 및 정보를 입수할 수 있다.
사용자 요구사항 만족을 위한 기능 정의 및 기능별 정량목표
- 여행지 노트 추천
- 사용자 선호도 조사 및 로그 수집
- 추천 알고리즘 실행
- 여행지에 대한 평가 및 정보 입수
- 타이틀, 사용자 이름 검색 시 연관 정보를 제공
개념설계안
- 사용자 인증
- JWT는 유저를 인증하기 식별하기 위한 토큰 기반 인증입니다. 세션과는 달리 서버가 아닌 클라이언트에 저장되기 때문에 서버의 부담을 훨씬 덜 수 있습니다.
- Restful의 경우 무상태성이 큰 특징인데 유저의 인증이라는 ‘상태’를 담아야하기 때문에 패러다임의 충돌이 생기게 됩니다. 따라서 토큰 자체에 사용자 권한 정보나 서비스를 사용하기 위한 정보가 포함되어있습니다. 해당 토큰들은 Redis 상에서 관리되게 되고 access token의 경우 30분, refresh token의 경우 30일의 유효 기간이 존재합니다. access token이 만료되었다면 refresh token을 통해 다시 access token을 재발급받아 서버에 접속 가능합니다.
- JWT를 사용하면 클라이언트에서 id, password를 통해 웹서비스 인증을 진행합니다. 해당 id, password가 일치한다면 서버에서 서명된 JWT를 생성해서 클라이언트에게 돌려줍니다. 이후 클라이언트는 인증이 필요한 페이지에 접속할 시 header에 access token을 포함하여 전송하게 됩니다. 그 후 서버는 access token의 유효성을 검사하고 유효하다면 내부 filter에서 걸러지지 않고 접속을 허락하게 됩니다.
- 데이터 전처리
- 데이터 크롤링의 경우 네이버 리뷰, 다음 리뷰, trip advisor 3개의 플랫폼에서 리뷰를 가져오려고 하였습니다. Trip advisor, 네이버 리뷰, 다음 리뷰에서 합계 총 53만 개의 리뷰를 추출하였습니다.

- 전처리의 경우 한양대 여행 경로 추천 논문에서 20개 이상의 리뷰를 가진 유저나 POI만 전처리했던 것을 토대로 같은 전처리를 수행하였고 최종적으로 약 8만 개 정도의 리뷰를 사용하였습니다.
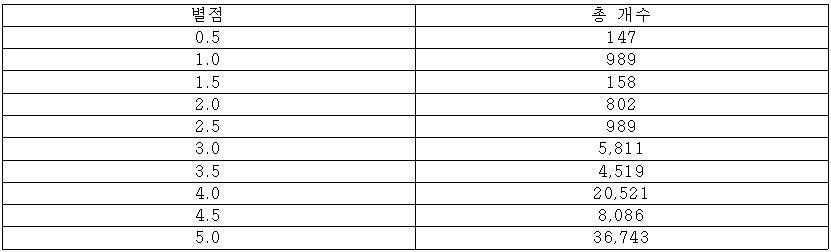
- Rating data의 경우 다음과 같은 분포를 가집니다. 별점 5.0점에 굉장히 skew되있는 것을 확인할 수 있습니다. 실제로 예측이 5점으로 많이 분포되었기 때문에 test set의 에러가 0.57점으로 낮게 나오더라도 좋은 모델이라고 보기에는 힘들다고 생각합니다.


- 추천 시스템 개발
- 저희는 다음과 같이 3가지의 모델을 고려하였습니다.
- Dataset 종류의 경우 explicit dataset과 implicit dataset가 존재합니다. Explicit dataset의 경우 user가 item에 남긴 별점 자체를 회귀 분석을 통해 예측하도록 하는 dataset이고 implicit dataset의 경우 user가 item에 남긴 상호작용을 0 또는 1로 표현하는 dataset으로 binary classification으로 예측이 이루어져야합니다. 저는 두 가지 방법 모두 사용하여 실험하였습니다.
Item-based Collaborative Filtering
- dataset 종류, 유사도, 예측 방법, 알고리즘 순으로 설명드리겠습니다.
- Dataset 종류의 경우 explicit dataset과 implicit dataset가 존재합니다. Explicit dataset의 경우 user가 item에 남긴 별점 자체를 회귀 분석을 통해 예측하도록 하는 dataset이고 implicit dataset의 경우 user가 item에 남긴 상호작용을 0 또는 1로 표현하는 dataset으로 binary classification으로 예측이 이루어져야합니다. 저는 두 가지 방법 모두 사용하여 실험하였습니다.
- 사용하는 유사도는 cosine 유사도, correlation 유사도, adjusted cosine 유사도를 사용합니다.
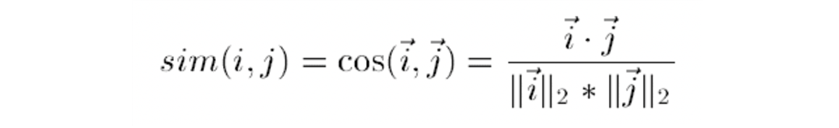
- 먼저, cosine 유사도는 item i, j의 rating vector를 cosine 내적하여 유사도를 구하는 방식입니다.
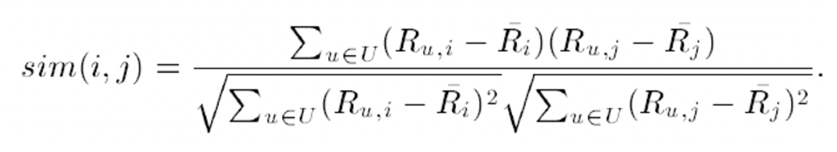
- 다음으로 correlation 유사도는 rating 자체를 item rating의 평균을 빼고 분산을 나누어주어 표준화를 거친 후 cosine 유사도를 측정하는 방식입니다.
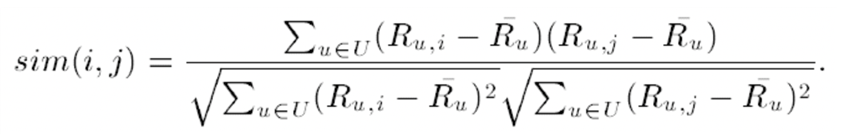
- 마지막으로 adjusted cosine 유사도의 경우는 correlation 유사도에서 평균과 분산을 item rating 대신 user rating을 사용한 것입니다. 즉, user의 별점을 주는 성향까지 추가로 고려한 방식으로 해당 논문에서는 adjusted cosine 유사도 방식이 제일 좋은 결과가 나왔습니다.



- 예측 방법입니다. Weighted sum 방식과 regression이 존재합니다.
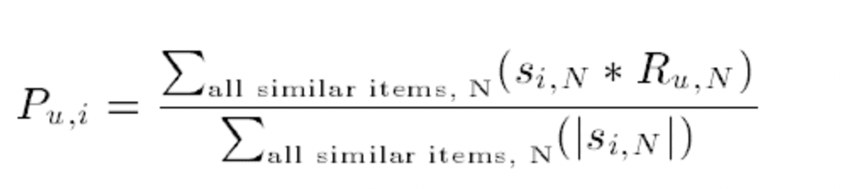
- Weighted sum의 경우 유사도(0~1 사이로 표시됨)와 rating을 곱하여 유사도가 높은 item의 rating이 더 많이 반영되도록 한 예측 방법입니다.
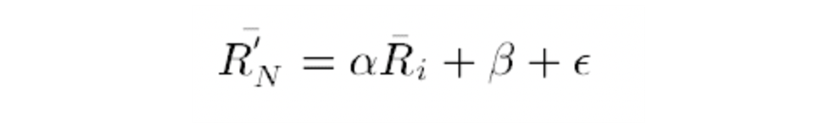
- Regression의 경우 weightecd sum과 동일한 산식을 쓰지만 2 개의 item vector가 유클리드 거리는 멀지만 유사도가 높게 나오는 경우 때문에 예측 정확도가 떨어질 수 있음을 고려한 방법이라고 논문에 등장합니다.


- 최종적으로 적용했던 알고리즘 로직을 설명드리겠습니다.
- PlaceReview 테이블에 저장되어있는 리뷰 데이터를 전부 불러와서 user, place 각각 리뷰가 20개 이상인 것만 추출하여 전처리합니다. 그 후 별점이 없는 부분은 0점으로 만들어 explicit dataset matrix를 구성합니다. 이 때, target으로 하는 user가 방문하지 않았던 place와 방문한 Place를 구분하여 추출합니다. 그 후, 방문하지 않은 장소와 방문했던 장소들과의 item similarity 값을 3가지 유사도 방법 중 하나를 사용하여 추출합니다. 그 다음 해당 유사도와 가본 장소의 rate를 weighted sum 방식으로 합산하여 최종 예측 별점을 추출합니다. 마지막으로 안 가본 장소들의 예측 rating을 내림차순 정렬하여 추천 받을 장소 개수대로 유저에게 top N개를 제공합니다.
Neural Collaborative Filtering
- 해당 알고리즘은 기존 Matrix Factorization의 한계점으로부터 제안되었습니다. 기존 Matrix Factorization의 한계점은 user와 item 간의 복잡한 관계를 표현하는데 한계가 있음을 지적하였습니다.
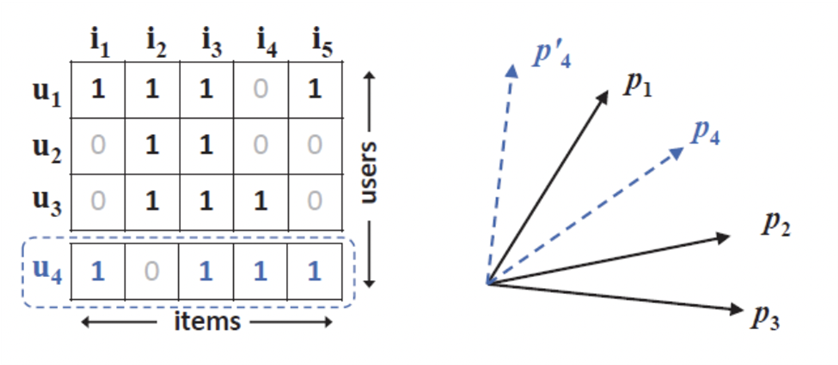
- Sij는 user i와 j의 유사도를 나타낸다고 가정합니다. 그 때, user 2와 3이 가장 비슷하고 user 1과 3이 가장 덜 비슷하다는 결과가 나옵니다. 하지만 새로운 user 4가 들어올 때 4와 1이 가장 비슷하고 4와 2가 가장 비슷하지 않게 유사도가 나오게 됩니다. 그렇게 되면 p1과 가까운 동시에 p2를 가장 멀리하는 p4 벡터를 찾을 수 없습니다. 즉, user와 item을 저차원에 단순한 공간에서 표현하는데에 있기 때문에 neural network 구조를 추가하여 관계에 복잡성을 더하는 것입니다.

- 모델 구조는 user one-hot vector를 embedding layer에 mapping하여 user latent vector를 만들고, item one-hot vector를 embedding layer에 mapping하여 item latent vector를 생성합니다. 해당 2개의 vector를 concatenate한 것을 DNN 구조에 통과시켜 기존 gradient descent 방식으로 학습하는 것이 목표입니다. 이 때, 예측하는 지표의 경우 0 또는 1의 binary 값인데 그 이유는 해당 알고리즘에서 별점을 직접적으로 활용하는 explicit dataset보다 유저와 item의 상호작용을 0 또는 1로 표시하는 Implicit dataset 방법을 골랐기 때문입니다. 논문에서는 해당 알고리즘에 implicit dataset이 효과가 좋다고 나와있습니다.
- 최종적인 NeuMF 구조의 경우에는 위에서 설명했던 MLP 구조에 Matrix Factorization을 추가로 수행하는 GMF Layer를 추가하여 최종 예측을 수행합니다. 최종 모델 구조는 다음과 같습니다.
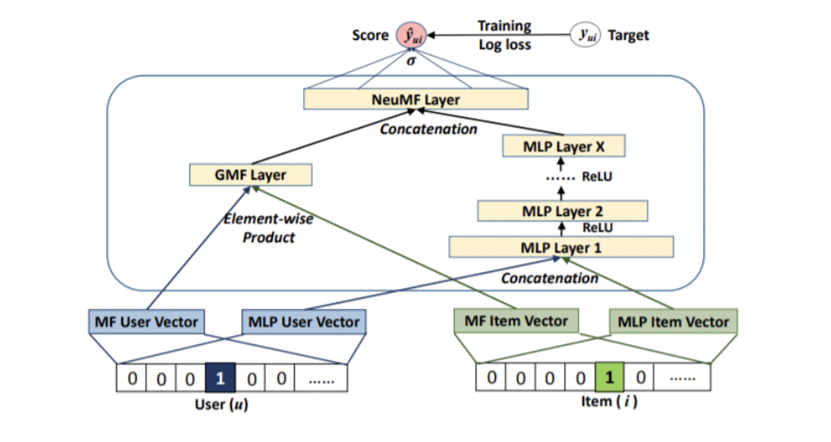

최종 사용한 모델
- Neural Collaborative Filtering, Youtube DNN의 경우 논문의 요점 파악과 코드로의 재현이 어려웠던 점, Backend 개발과 AI 모델 개발을 병행하다보니 발생하는 시간적인 문제 때문에 구현에 실패하였습니다. 따라서 Item-based Collborative Filtering에서 유사도 측정, dataset 종류, 예측 계산에 있어서 모든 조합을 고려하여 최종적으로 Mean Average Error를 계산하였을 때 Correlation based similarity, weighted sum, explicit dataset을 사용하였을 때 0.57점 정도의 평균 에러가 발생하였고 해당 에러가 최선의 결과였습니다. 한양대 논문 상에서는 1.2점의 MAE 에러가 나왔는데 더 좋은 결과가 나왔다고 볼 수 있습니다. 하지만, 예측 자체가 skew된 5.0점을 주로 예측하여서 측정 에러 값이 낮은 편이어도 적절한 예측이 이루어졌다고 보긴 어렵다고 판단하였고 저희 프로젝트에 다양한 모델 적용을 못한 것이 아쉽습니다.
- DB 설계
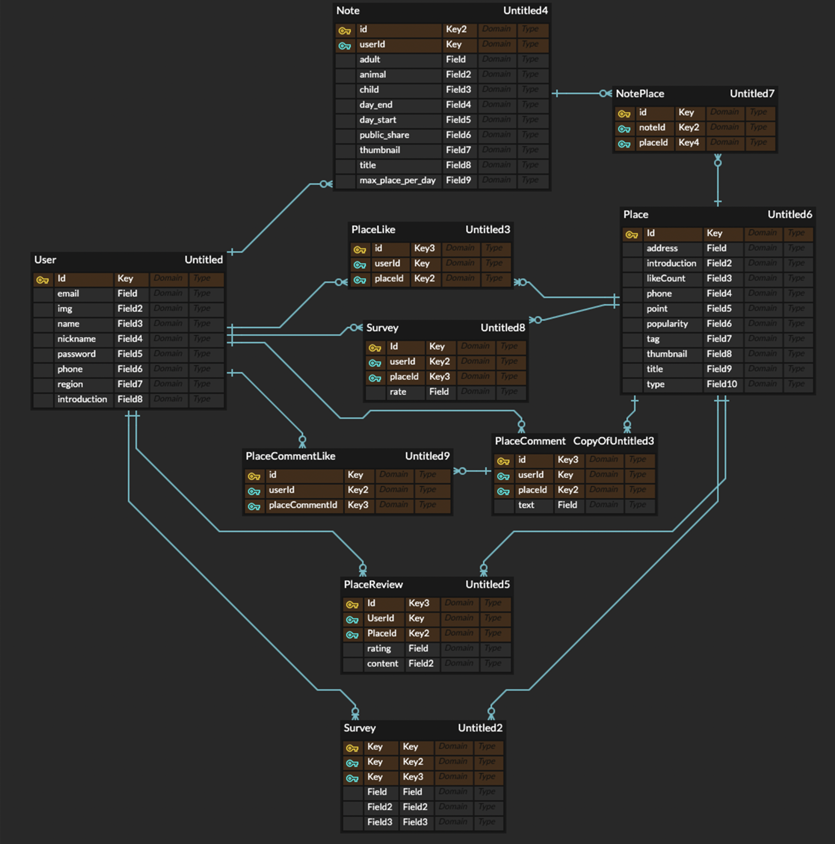
- 설계한 erd입니다. Erdcloud를 통해 테이블을 생성하였습니다. 모든 table에는 PK인 id와 row가 생성된 날짜를 표시하는 createdAt column, 업데이트된 날짜를 표시하는 updatedAt column이 공통적으로 존재합니다.

- 먼저, user table입니다. User와 관련된 인적사항 및 인증 관련 column을 저장합니다. Img의 경우 user profile picture가 들어가게 되는데 s3에 user 프로필 이미지를 저장하고 해당 s3의 이미지 링크를 img column에 저장합니다. 이후 프론트엔드에서 해당 링크에 해당되는 이미지를 띄워주게 됩니다. Password의 경우 내부에서 원래 password를 다른 문자열로 encoding하는 방식으로 저장하여 password를 DB 상에서 확인할 수 없게 하였습니다.
- 두번째로, note table입니다. Note라는 것은 유저의 여행 노트를 말하는 것인데 유저 한 명이 여러 개의 노트를 생성할 수 있는 1:n 관계입니다. Adult, Animal, Child는 각각 여행가는 성인, 애완동물, 아이 수를 뜻하며 day_end, day_start의 경우 여행 시작 날짜와 종료 날짜 각각을 저장합니다. Public share의 경우에는 해당 여행 노트를 다른 사람들에게 공유할지 여부를 뜻하며 thumbnail은 여행 노트의 썸네일 이미지 s3 링크, title은 노트 제목, max_place_per_day는 하루 당 몇 개의 관광지를 추천받을지 저장합니다. 해당 column 정보들을 통해 flask 내부에서 여행 일수를 계산하고 max_place_per_day를 통해 총 추천받을 관광지 개수를 계산해서 추천 시스템 로직을 통해 유저에게 제공합니다. 추가로 옆에 NotePlace 테이블의 경우에는 유저에게 최종 추천해준 장소를 저장하는 table입니다.
- 세 번째로 Place입니다. 장소의 이름, 전화번호, 주소, 여행지 태그가 기본적으로 저장됩니다. Point라는 column은 Spring 내부적으로 Point라는 클래스로 위도 경도를 저장합니다. 프론트엔드가 해당 point column 값을 받아 카카오 api 상에 장소 위치를 표시합니다. likeCount같은 경우에는 장소에 좋아요가 몇 개인지 저장하는 역할을 합니다. PlaceLike에서 해당 Place 관련 row가 몇 개인지 세는 방법으로 좋아요를 구하는 방법도 있지만 Join 연산으로 인해 조회가 오래걸리는 것을 고려해서 파생 column을 만들어 부하를 줄여주는 방법을 택한 것입니다.
- 마지막으로 User와 Place 사이에 m:n 형식으로 여러 table들이 존재합니다. User가 Place에 남길 수 있는 좋아요가 PlaceLike 테이블로, 댓글이 PlaceComment 테이블로, 리뷰가 PlaceReview 테이블로 나타납니다. PlaceReview 테이블의 경우 별점과 내용이 저장되는데 이전에 크롤링했던 데이터 53만 개의 데이터가 해당 table로 import됩니다. Survey의 경우 유저가 회원가입 시 기본으로 20개의 랜덤 place에 대한 rating을 매길 수 있도록 하였습니다. Survey가 작성되면 내부 비즈니스 로직에서 자동으로 PlaceReview 테이블에도 row로 추가됩니다.
- 최종 아키텍처
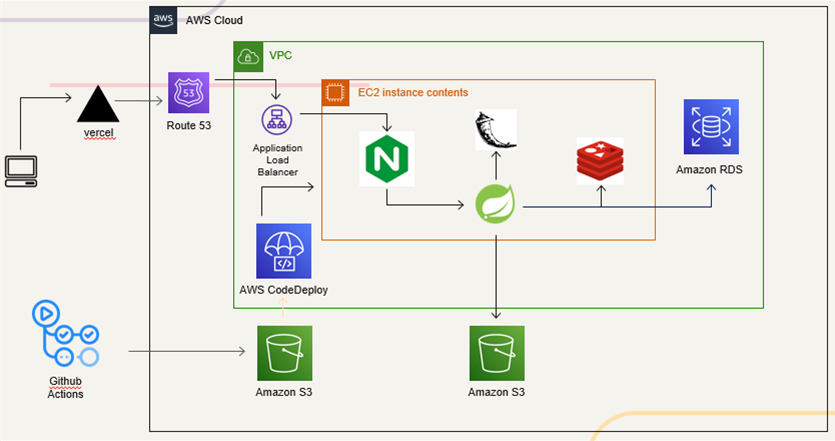
- Vercel로 frontend 배포를 하고 frontend에서 도메인 주소에 접속하면 route 53에서 해당 도메인에 해당되는 ec2로 안내를 도와줍니다. 백엔드 부분의 경우 code deploy와 s3를 사용해서 ec2 상에 코드를 배포하게 되고 docker 환경을 사용하여 배포를 하게 됩니다. 도커 환경에는 nginx, spring, redis, flask가 존재합니다. Nginx를 사용한 이유는 정적 페이지의 경우 web application server인 spring이 처리하지 않고 대신 페이지를 return해주어 부하를 줄여주기도 하고 하나의 스레드가 여러 요청을 처리하기 때문에 많은 트래픽에 상당한 강점을 가지고 있습니다. spring은 web application server로서 전체적인 DB crud를 맡는 즉, 동적인 웹 요청을 맡는 비즈니스 로직을 실행합니다. Flask의 경우는 추천 시스템 알고리즘 자체를 python으로 작성하였기 때문에 flask로 요청을 받는 것이 유리할 것이라고 판단하여 사용하였습니다. Spring에서 추천 관련 요청을 flask로 보내면 flask가 추천 경로를 응답하여 돌려줍니다. redis의 경우는 cache의 장점도 있고 redis 상에서 토큰 유효기간이 지나면 자동으로 삭제해주는 시스템을 활용하는 장점이 있습니다. Cache의 경우 로그인 요청이 온 유저에 대해 60초 정도 cache를 유지합니다. 또한, 관계 DB에서 토큰을 관리하면 일일이 관계 설정을 해야되는 번거로움이 있기에 nosql인 redis를 사용하였습니다. DB의 경우 rds 관계 DB를 활용하고 ec2와 rds를 같은 VPN 상에 두어 서로 통신이 가능하게 합니다.

- 추가로 github actions와 aws code deploy를 같이 사용하여 continuous deployment를 구현하였고 코드를 push할 시 자동으로 ec2 내부에 배포되도록 하였습니다.
유스케이스 다이어그램
액터 목록

유스케이스 설명







결과 및 평가
완료 작품의 소개
프로토타입

- 대표 기능 화면입니다. 설문조사 완료 후 사용자 맞춤 여행 계획을 짤 수 있습니다.
실행
SW 실행 방법

- 사이트 접속 후 로그인 화면입니다.
- 이메일과 비밀번호에 정규표현식을 삽입해 이메일과 비밀번호 양식이 모두 맞을 때 로그인 버튼이 활성화되도록 구현했습니다.

- 회원가입 화면입니다.
- 이메일, 비밀번호, 닉네임, 핸드폰 번호, 이름, 거주 지역을 정보로 입력받고 있고 필수정보가 모두 입력되어야 회원가입 버튼이 활성화되도록 구현했습니다.

- 로그인 후 이용자의 여행지 성향을 분석하기 위한 설문조사 시작 화면입니다.

- 설문조사 화면의 예시입니다.
- 설문조사 상단에 상태 바를 구현하여 사용자가 몇 번째 설문을 하고 있는지 실시간으로 확인할 수 있고 점수를 매길 수 있는 간단한 별표 UI를 라이브러리를 사용해 구현했습니다.

- 설문조사 완료 후 화면입니다.

- 설문조사 완료 후 사용자 맞춤 여행 계획을 짜기 위한 시작페이지입니다.
- 여행 일정, 여행 제목, 여행 인원, 외부 공유 버튼, 여행지 개수를 필수 값으로 입력 받고 있고 외부 공유와 여행지 개수는 default 값이 설정되어 있습니다. 필수 값들이 모두 입력되어야 여행지 완성 버튼이 활성화됩니다. 꼭 추가해야할 여행지에는 사용자가 여행을 하면서 꼭 방문하고 싶은 여행지를 추가할 수 있습니다. 여행지에 검색어를 입력하면 백엔드 서버로 api를 호출해 리스트를 가져옵니다. 이 때 디바운스를 적용해서 불필요한 api 호출을 방지했습니다.

- 사용자 맞춤형 여행 코스 페이지입니다.
- 사용자가 입력한 정보를 바탕으로 사용자 취향에 맞게 여행지를 추천해주는 페이지입니다. 여행지 추천 기능뿐만 아니라 링크 공유, 동선 최적화, 동행자 추가, 비슷한 성향의 여행자가 만족한 여행지 추천, 숙소 추천, 맛집 추천, 항공권 예매, 네이버 길찾기 리다이렉션, 여행지 순서 변경과 같은 기능들을 제공합니다.

- 여행지의 상세 정보를 보여주는 페이지입니다.
- 여행지마다의 상세 정보를 보여줍니다. 반려동물이 입장가능한지 아이들을 위한 여행지인지 운영시간, 입장료, 상세 설명과 같은 정보가 있고 구글 번역 api를 사용해 영문으로도 정보를 받아볼 수 있습니다.
성과물
포스터
대외전시 포스터

- 여행객들이 관심을 가질만한 디자인으로 사이트 로고를 준비했습니다.
- 여행이라는 테마를 한눈에 알 수 있게 비행기와 캐리어 그림을 사용해 아이콘을 만들었습니다.
- 제주도를 대상으로 하는 걸 제주라는 사이트 이름과 귤을 상징하는 오렌지색으로 표현하였습니다.
완료작품의 평가


향후평가
어려웠던 내용들
- 네이버와 카카오 두 플랫폼에서 상당한 양의 여행지 데이터를 수집하였으나, 리뷰가 적은 데이터가 많아 전처리 후 쓸만한 데이터가 많이 남지 않았다. 또한, 어떤 정보를 추천 시스템에 사용할지 정하는 데에 대한 어려움이 있었다.
- 확도가 높은 추천 시스템을 위해 어떤 알고리즘을 적용시켜야 하는지 정하기 어려웠다.
- 깔끔하면서도 직관적인 웹 디자인을 고심하여여 제주를 상징하는 오렌지색을 테마로 하였다.
차후 구현할 내용
- 리뷰 수가 적어 사용하지 못했던 장소 데이터의 정보를 찾아 추천 여행지 늘리기
- 게시판이나 포토갤러리 등을 구현해 이용자 간 정보 공유 활성화를 유도
- 사용했던 추천 알고리즘이 적절한지를 확인하고 더욱 최적화시키기
- 더욱 깔끔한 이용자 경험을 위해 디자인 다듬기
개발 사업비 정산
구성원 및 추진체계
- 개인
- 원우인: 네이버, 다음, 기타 여행 앱으로부터의 데이터 크롤링, personalized trip recommendation system 알고리즘 개발, Frontend/Backend 사이 api 구성 및 전체적 설계 담당, AWS 배포 담당
- 이동기: 사용자가 사용하기 편리한 UI/UX 구성, 서버로의 request 전송/ 서버로부터의 response 다루는 Frontend 구성 역할
- 이동준, 윤예준: 데이터 크롤링, 서류 작성 및 관리
- 팀
- 필요시 팀원 당 플랫폼 하나씩 선정하여 데이터 크롤링 담당
- 발표 자료 혹은 발표의 경우 돌아가며 전담
관련사업비 내역서

부록
A-1 참고문헌 및 참고사이트
- Personalized Tour Recommendation via Analyzing User Tastes for Travel Distance, Diversity and Popularity - JongsooLee, Jung Ah Shin, Dong-Kyu Chae and Sang-ChulLee
- Item-Based Collaborative Filtering Recommendation Algorithms - BadrulSarwar, George Karypis, Joseph Konstan, and John Riedl
- Neural Collaborative Filtering – XiangnanHe, LiziLiao, HanwangZhang, LiqiangNie, XiaHu, Tat-SengChua
- Deep Neural Networks for YouTube Recommendations- Paul Covington, Jay Adams, Emre Sargin
A-2 관련특허
A-3 소프트웨어 프로그램 소스
- https://github.com/zs-capstone -- backend, AI, 배포 코드 존재
- https://github.com/zs-capstone/Frontend -- Frontend 코드 존재