2분반-이루매납치단
프로젝트 개요
기술개발 과제
- 국문 : 웹 개발자(워드프레스 이용자)를 위한 취약점 탐지 및 자동 침투 서비스
- 영문 : Vulnerability Detection and Automated Pentesting Service for Web Developers (for WordPress Users)
- 서비스명 : AutoPwn
과제 팀명
이루매납치단
지도교수
이경재 교수님
개발기간
2026년 3월 ~ 2026년 6월 (총 4개월)
구성원 소개
서울시립대학교 컴퓨터과학부 20209200** 이*원(팀장)
서울시립대학교 컴퓨터과학부 20209200** 이*민
서울시립대학교 컴퓨터과학부 20215600** 이*형
서울시립대학교 컴퓨터과학부 20219200** 최*영
서론
개발 과제의 개요
개발 과제 요약
- AutoPwn은 WordPress 플러그인 소스코드를 업로드하면 ① 취약점을 찾고 ② WordPress 환경을 자동으로 빌드하여 ③ 실제로 공격해 증거까지 제시하는 자동 침투 테스트(Automated Penetration Testing) 플랫폼이다. 탐지 · 환경구축 · 실시간 공격 실행 · 증거 수집의 전 과정을 하나의 파이프라인으로 자동화한 통합 보안 솔루션이다.
- AI 기반 하이브리드 정적분석(SAST + LLM)으로 플러그인 내 주요 보안 취약점을 식별하고, Docker로 격리된 샌드박스에서 익스플로잇(Exploit)을 자동 실행하여 검증한다. 검사기(oracle)가 실제 공격 성공 여부를 기계적으로 판정하므로, "취약할 수 있다"가 아니라 "실제로 공격에 성공했다"는 증거를 제공한다.
- WordPress 취약점 지식 기반(RAG)에서 공격 기법을 검색하여 대상 플러그인에 최적화된 PoC(Proof-of-Concept)를 자율 생성하고, 발견된 취약점에 대한 상세 기술 보고서와 실제 공격 성공 사례를 시각화해 제공한다.
- 또한 개별 취약점을 연결한 복합 공격 체인(진입점 → 권한 상승 → 데이터 유출 → 시스템 장악)을 자동 분석·그래프화한다. 보안 비전문가도 소스코드 업로드 후 버튼 한 번으로 5단계 전 과정을 수 분 ~ 수십 분 내에 완료할 수 있다.
개발 과제의 배경
- 전 세계 웹사이트의 43.6%를 점유하는 WordPress는 검증되지 않은 서드파티 플러그인을 통한 보안 위협이 끊이지 않는다. Patchstack(2024) 기준 보안 사고의 96%가 플러그인에서 발생하고, 2024년 한 해에만 플러그인 취약점 7,633건(하루 평균 22건)이 보고되었으며, 등록 플러그인 59,000여 개 중 59%가 2년 이상 미업데이트로 방치되어 있다.
- 취약점 공개 후 악용 시작까지는 중앙값 약 5시간(24시간 내 45%, 7일 내 70%)인 반면, 개발자 패치 배포에 평균 14~21일 · 관리자 적용에 추가 14일이 걸려 구조적 시간 격차가 크다. 2025년 Claude를 악용한 자율 해킹 사례(GTG-1002)가 작전의 80~90%를 AI로 자율 수행한 것처럼, 방어 측의 자동화 대응이 시급하다.
- 기존 정적분석 도구(Semgrep, CodeQL 등)는 오탐률 91%(Ghost Security 2025) · 미탐률 47~80%(Endor Labs)로 "취약할 수 있다"는 경고에 그치고, WPScan 등 WordPress 전용 도구는 자체 CVE DB의 알려진 취약점만 매칭해 0-day와 커스텀 플러그인은 탐지하지 못한다.
- 무엇보다 정적분석 → 환경구축 → 공격 실행 → 증거 수집 → 리포트를 하나로 잇는 통합 파이프라인이 부재하여 단계 전환마다 전문가 개입이 필요하다. AutoPwn은 이 전 과정을 자동화하고, 단순 경고가 아닌 실제 공격 성공 사례와 시각화된 공격 체인 리포트로 개발자가 심각성을 즉시 인지해 배포 전에 수정하도록 돕는다.
개발 과제의 목표 및 내용
목표 : WordPress 플러그인을 대상으로 "소스코드 → 실제 Exploit 실증"을 5단계(정적분석 → 재검증 → PoC 생성 → Exploit 실행 → 리포트)로 통합한 자동 분석 파이프라인을 캡스톤 기간 내 구현한다.
세부 내용
- ① Runtime Builder : 플러그인의 PHP 헤더 · composer.json · readme.txt를 파싱해 요구 PHP/WP 버전을 자동 판별하고 WordPress + MySQL + 플러그인 + 역할별 테스트 계정(administrator, editor, subscriber, 비로그인)을 Docker로 자동 구축한다.
- ② 정적분석 : PHP AST로 엔드포인트 · nonce · REST 인증 · 역할별 권한을 수집해 App Context를 만들고, SAST + LLM 교차검증으로 취약점 후보를 도출한다.
- ③ PoC 자율 생성 : 취약점 유형 + App Context로 대상 플러그인의 실제 AJAX action · REST route · 파라미터 · 인증 방식에 맞춰 LLM이 PoC를 생성한 뒤 구문 검사 · dry-run · 실패 피드백으로 최대 3회 자가 수정한다.
- ④ Exploit 실행 : 격리 랩에서 PoC를 실제 실행하고 oracle이 성공을 판정한다.
- ⑤ 리포트 : 진입점 → 권한 상승 → 데이터 유출의 복합 공격 경로 시각화, 심각도 분포 차트, 권한별(비인증/subscriber/admin) 공격 표면 매핑, 증거 파일 뷰어, CVSS · CWE · 패치 제안을 제공한다.
- 전체 시스템은 사용자별 프로젝트 · 이력 관리와 진행률 실시간 표시를 갖춘 SaaS 형태로 제공된다.
관련 기술의 현황
관련 기술의 현황 및 분석(State of art)
전 세계적인 기술현황
- LLM 기반 코드 보안 : Google Project Zero의 Big Sleep(2024)이 LLM 에이전트로 SQLite의 0-day(스택 버퍼 언더플로우)를 세계 최초로 발견하여 AI의 취약점 연구 기여 가능성을 입증했다. 국내에서는 토스가 Semgrep + Qwen3 Multi-Agent로 특정 평가셋 기준 정확도 100%를 보고했다.
- 자동 익스플로잇 생성 : 2016년 DARPA Cyber Grand Challenge에서 CMU의 Mayhem이 세계 최초 전자동 해킹 대회에서 우승하여 자율 해킹 가능성을 입증했다(Symbolic Execution 기반 자동 exploit 생성 특허 US9135405B2 등록). 최근에는 PwnGPT(ACL 2025)와 다중 에이전트 exploit 생성 프레임워크(2026) 등 자가 수정 루프 기반 LLM PoC 생성 연구가 활발하다.
- RAG 기반 접근 : 취약점 DB와 기술 문서를 벡터화하여 유사 공격 기법을 검색하는 RAG가 확산 중이며, WordPress 취약점은 패턴이 반복적(SQLi, XSS, CSRF 등)이어서 RAG가 특히 효과적인 도메인이다.
- 기존 SAST 한계 : Ghost Security(2025)는 웹 애플리케이션 정적분석 사례군에서 오탐률 91%를, Endor Labs는 분석 대상 · 규칙 구성에 따라 미탐률 47~80%를 보고하여 단일 정적분석의 신뢰성 한계를 드러냈다. 이는 LLM을 통해 기존 정적분석의 한계를 확장할 수 있음을 시사한다.
특허조사 및 특허 전략 분석
Google Patents를 통해 AutoPwn 관련 분야의 선행 특허를 조사하였다.
| 특허번호 | 출원인 | 핵심 기술 | AutoPwn과의 차이 |
|---|---|---|---|
| US20250315533A1 (2025) | Capital One | LLM 기반 위협 모델 자동 생성 및 침투 테스트 스크립트 생성 | 위협 모델링 중심, 실제 Exploit 실행·검증 없음 |
| US20210357507A1 (2021) | (개인 출원) | Attack-tree 기반 분산 자동 침투 테스트 프레임워크 | 룰 기반 의사결정 트리, LLM/RAG 미사용 |
| US20240333765A1 (2024) | (출원) | LLM 생성 허니팟 기반 사이버 기만 시스템 | 방어(기만) 목적, 취약점 탐지·exploit 생성과 무관 |
AutoPwn의 특허 가능 요소로는 "WordPress 취약점 PoC 자율 생성 및 자가 수정 루프"와 "소스코드 분석부터 Docker 환경 자동 빌드 및 Exploit 실행까지의 WordPress 특화 통합 파이프라인"이 있다. Local LLM 기반 PoC 자율 생성 + WordPress 특화 화이트박스 분석 + Docker sandbox 실행 검증이라는 조합의 선행 특허는 확인되지 않아 신규성을 주장할 수 있다.
기술 로드맵
AutoPwn 관련 기술의 발전 흐름과 본 과제의 위치를 아래와 같이 정리하였다.
| 시기 | 정적분석 | 동적분석/Exploit | 통합도 |
|---|---|---|---|
| ~2015 | 전통 SAST (Coverity, Fortify) | 수동 모의해킹 | 단일 도구, 수동 연결 |
| 2016 | - | DARPA CGC; Mayhem 자율 해킹 | 자동화 가능성 입증 |
| 2019~2020 | 차세대 SAST (Semgrep, CodeQL) | CVE DB 매칭 자동화 (WPScan) | 도구별 부분 자동화 |
| 2024~2025 | Big Sleep: LLM을 통한 0-day 발견 | LLM 기반 PoC 생성 연구 | 개별 단계 AI 도입 |
| 2025~2026 | 토스: SAST+LLM | XBOW: AI 자동 침투 | 단계별 자동화 등장 |
| 2026 (현재) | AutoPwn: SAST+LLM+PoC+Exploit | 5단계 통합 파이프라인 | |
| 미래 | 완전 자율 코드 감사 | 자동 패치 생성+배포 | CI/CD 완전 통합 |
AutoPwn은 "개별 단계 AI 도입"에서 "통합 파이프라인"으로의 전환점에 위치하며, 토스(탐지만)와 XBOW(블랙박스만)를 화이트박스 + Exploit으로 결합한 다음 단계를 목표로 한다.
시장상황에 대한 분석
경쟁제품 조사 비교
AutoPwn과 기술적으로 유사한 두 가지 솔루션(토스 시스템, XBOW)과 기존 WordPress 보안 도구 대표 1종(WPScan)을 비교 분석하였다.
- 토스 시스템 : 토스 보안팀의 내부 전용 시스템으로 Semgrep(SAST)과 오픈 LLM(Qwen3:30B)을 결합한 Multi-Agent 아키텍처. 공개 사례에서 특정 평가셋 기준 정확도 100%를 보고했으나, 정적분석 수준에 머물러 PoC 생성·Exploit 실행이 없고 비공개 내부 시스템이라 외부 사용이 불가하다.
- XBOW : 수천 개의 AI 에이전트가 병렬로 웹 애플리케이션에 자동 침투 테스트를 수행하는 상용 플랫폼. 자동 PoC 생성과 비파괴적 Exploit 검증, SOC2 · ISO 27001 컴플라이언스 리포트를 제공하나, 블랙박스 방식이라 소스코드를 분석하지 않으며 건당 $4,000~6,000의 고가 요금과 5영업일 대기는 소규모 개발사에 비현실적이다.
- WPScan : WordPress 전용으로 가장 널리 쓰이는 블랙박스 스캐너. 자체 CVE DB의 알려진 취약점만 매칭하며 소스코드 분석 · 0-day 탐지 · PoC 생성 기능이 없다.
| 비교 항목 | 토스 시스템 | XBOW | WPScan | AutoPwn |
|---|---|---|---|---|
| 분석 방식 | 화이트박스 (SAST+LLM) | 블랙박스 (AI) | 블랙박스 (CVE DB) | 화이트박스 (SAST+LLM+동적) |
| 소스코드 분석 | O | X | X | O |
| 자동 PoC 생성 | X | O | X | O |
| 실제 Exploit 실행 | X | O | X | O |
| 0-day 탐지 | O | O | X | O |
| 대상 사용자 | - | 엔터프라이즈 | 누구나 | 소규모 개발자 |
| 가격 | - | $4,000~$6,000/건 | 무료~$400/yr | 월 구독 / 토큰 종량제 |
AutoPwn은 ① 소스코드 분석(화이트박스)부터 PoC 자율 생성, Exploit 실행까지를 하나의 파이프라인으로 통합하고, ② WordPress 플러그인의 AJAX action · REST route · nonce · 역할별 권한 등 내부 구조를 이해·활용하는 특화 도구이며, ③ 월 구독료 수준의 접근성을 목표로 한다는 점에서 차별화된다.
마케팅 전략 (SWOT)
| S (강점) | W (약점) |
|---|---|
| 화이트박스 + Exploit 통합 파이프라인, WordPress 특화, 간편한 UX, 보안 커뮤니티 플랫폼 내장 | WordPress 플러그인만 대상, 학부 프로젝트 규모, GPU/LLM API 비용 의존 |
| O (기회) | T (위협) |
| WP 플러그인 취약점 연 7,633건 폭증, 플러그인 59% 미업데이트 방치, 소규모 개발사의 모의해킹 비용 부담, AI 보안 시장 연 23.6% 성장 | XBOW 등 상용 플랫폼 고도화, 기존 도구의 AI 통합 추세(Semgrep AI 등), 자동 해킹 도구 윤리/규제 이슈 |
AutoPwn은 XBOW 같은 엔터프라이즈 고가 솔루션과 다른 시장을 노린다. 핵심 전략은 ‘간편성’과 ‘가벼움’이다. XBOW가 범위 설정 · 인증 구성 · 5영업일 대기를 요구하는 반면, AutoPwn은 소스코드 업로드 후 버튼 하나로 수 분 내 결과를 제공하여 소규모 개발자의 모의 해킹 접근성을 확대한다. 또한 단순 분석 도구를 넘어 WordPress 보안 개발자 커뮤니티 플랫폼(취약점 정보 공유 · 보안 토론 게시판)으로서 부가가치를 제공하여 커뮤니티 기반 사용자 유지율 제고를 추구한다. 타겟 고객은 보안 전문인력이 없는 WordPress 플러그인 소규모 개발사 및 프리랜서 개발자이다.
개발과제의 기대효과
기술적 기대효과
- 실제 Exploit 실행 검증으로 SAST의 높은 오탐(사례군 91%)을 걸러내고, "취약할 수 있다"는 경고를 "실제로 공격에 성공했다"는 실증 보고로 결과 품질을 전환한다.
- WPScan · Patchstack 등 CVE DB 기반 도구가 탐지할 수 없는 커스텀 플러그인과 신규(0-day) 취약점을, 소스코드 직접 분석과 LLM의 패턴 인식을 결합해 탐지한다.
- 수동 모의해킹 2~4주, XBOW 5영업일이 걸리는 분석을 전 과정 자동화로 수 분 ~ 수십 분으로 단축하여, 취약점 공개 후 악용까지의 시간이 짧은 환경에서 방어 측 대응 속도를 높인다.
- 정적분석부터 보고서까지 5단계를 전체 자동 실행하고 구체적 패치 코드를 함께 제시하여, 비전문가도 소스코드 업로드 한 번으로 발견 즉시 수정할 수 있게 한다.
경제적, 사회적 기대 및 파급효과
- 건당 수천만 원의 전문 모의해킹, XBOW $4,000~6,000의 비용을 SaaS 월 구독료 수준으로 낮춰, 보안 전문인력이 없는 소규모 개발사 · 개인 개발자도 배포 전 침투 테스트를 수행할 수 있도록 접근성을 확보한다.
- NIST 연구에 따르면 개발 단계의 취약점 수정 비용은 운영 단계 대비 약 1/30 수준으로, 배포 전 사전 검증을 통해 데이터 유출 · 서비스 중단 · 평판 손실 등 사후 대응 비용을 원천적으로 절감한다.
- 전 세계 웹의 43.6%를 차지하는 WordPress의 플러그인 보안이 향상되면 인터넷 전반의 보안 수준 개선에 기여하고, 59% 미업데이트 방치 문제에 대한 개발자 인식을 제고한다. CVSS · CWE · 공격 체인 시각화 보고서로 비전문가도 위험도와 조치 방향을 즉시 파악해 보안 정보의 비대칭을 해소한다.
- 윤리적 측면 : 소스코드 업로드를 필수로 하여 본인 소유 플러그인만 테스트하도록 제한하고, 모든 공격은 Docker 샌드박스 격리 내에서만 실행되어 외부 시스템에 영향을 주지 않으며, 보고서에 패치 코드를 포함하여 공격이 아닌 방어 목적의 도구임을 명확히 한다.
기술개발 일정 및 추진체계
개발 일정
| 단계 | 세부 개발 내용 | 담당자 | 시기 | 비고 |
|---|---|---|---|---|
| 1 | 주제 선정 및 구체화 | 전원 | 3월 | |
| 2 | 개발 프로세스 및 개발환경 선정 | 전원 | 3월 | |
| 3 | 분석 대상(타겟) 선정 | 전원 | 3월 | |
| 4 | 요구사항 분석 및 정의 | 전원 | 3월 | |
| 5 | 취약점 수동 분석 및 사례 확보 | 이*형, 이*민 | 3~4월 | SAST 규칙 근거 확보 |
| 6 | Docker 기반 WordPress 플러그인 분석 환경 자동 구축 및 정보·엔드포인트 수집·자동화 | 이*형 | 4월 | 분석 컨텍스트 |
| 7 | 취약점 지식 데이터 수집 및 구조화 | 이*형 | 4월 | |
| 8 | 정적 분석(SAST) 엔진 설계 및 구현 | 이*형 | 4~5월 | 6·7 선행 |
| 9 | LLM 연동 및 SAST 통합 모듈 구현·검증 | 이*민 | 5월 | 8 선행 |
| 10 | PoC 생성 모델 구축 및 도메인 지식 주입 | 최*영 | 4~5월 | |
| 11 | PoC 생성 성능 평가 | 최*영 | 5월 | |
| 12 | 프론트엔드 및 UI/UX 설계·구현 | 이*원 | 4~6월 | 병렬 진행 |
| 13 | 취약점 실증(Exploit) 모듈 구현·검증 | 이*민 | 5월 | 9·10 선행 |
| 14 | 취약점 리포트 자동 생성 기능 구현 | 이*민 | 5~6월 | 13 선행 |
| 15 | AWS 백엔드 서버 구축 및 운영 자동화, 전체 통합 | 이*원 | 6월 | |
| 16 | 통합 테스트 케이스 분석 및 결함 수정 | 전원 | 6월 | 최종 안정화 |
구성원 및 추진체계
- 이*원 : 프론트 UI/UX, 백엔드 API 정의 및 스테이지 통합, 보고서·문서 작업
- 최*영 : Stage 3 설계 및 구현, 로컬 AI 엔지니어링
- 이*형 : Stage 1·2 설계 및 구현, 서비스 내 SAST 구축, 취약점 DB 수집, 취약점 수동 분석
- 이*민 : Stage 4 Exploit 체인 연결 및 구현, SAST 구축, Stage 5 리포트 설계
설계
설계사양
제품의 요구사항
필요사항(D, Demand)과 희망사항(W, Wish)을 구분하고 중요도를 대(大)·중(中)·소(小)로 등급화하였다.
| 번호 | 요구사항 | D/W | 중요도 |
|---|---|---|---|
| 1 | WordPress 플러그인 소스코드 자동 정적분석 (Git/ZIP 업로드) | D | 大 |
| 2 | SAST + LLM 교차검증으로 오탐률 50% 이하 | D | 大 |
| 3 | Docker 격리 환경 자동 빌드 (WordPress + MySQL + 플러그인) | D | 大 |
| 4 | LLM 기반 PoC 코드 자율 생성 및 실패 피드백 기반 재생성 루프 | D | 大 |
| 5 | Docker Sandbox 내 실제 Exploit 실행 및 증거 수집 | D | 大 |
| 6 | Exploit 시도 및 oracle 기반 성공 여부 판정 | D | 中 |
| 7 | 취약점별 CVSS · CWE · PoC 결과 포함 보고서 자동 생성 | D | 中 |
| 8 | 사용자별 프로젝트·분석 이력 관리 (회원가입/로그인) | D | 中 |
| 9 | 공격 흐름 및 취약점 관계 시각화 | W | 中 |
| 10 | 보안 개발자 커뮤니티 게시판 (CVE 토론·정보 공유) | W | 小 |
| 11 | CVE 백과사전 (CVE 검색기) | W | 小 |
설계 사양
제품 요구사항으로부터 6개 평가 항목과 가중치를 도출하고, 기능별 정량 목표를 확정하였다.
설계 사양 및 가중치
| 평가 항목 | 평가 내용 | 적용 기준 | 비중(%) |
|---|---|---|---|
| 분석 정확도 | LLM의 코드 이해·취약점 탐지 능력, SAST 오탐 보완 능력 | 오탐률(False Positive) 50% 미만 | 25.0 |
| 운영 비용 | 월 인프라 고정비 + LLM 토큰 변동비 합산 | 월 운영비 $50 이내 안정 유지 | 20.0 |
| 구현 가능성 | 다뤄야 할 기술 스택 양과 운영 복잡도 | 일정 내 5단계 파이프라인 구현 완료 | 20.0 |
| 응답 속도 | 사용자 요청 ~ 결과 출력까지 평균 소요 시간(콜드스타트 포함) | 240분 이내 결과 제공 | 15.0 |
| 데이터 보안 | 사용자 소스코드의 외부 사업자 전송 여부 및 격리 수준 | Exploit/PoC 코드 단계는 외부 비전송 | 10.0 |
| 확장성 | 동시 사용자/요청 폭증 시 자동 대응 능력 | 동시 10건 요청 처리 가능 | 10.0 |
기능별 정량 목표
| 기능 ID | 기능명 | 핵심 동작 | 정량 목표 |
|---|---|---|---|
| F1 | Stage 1 Runtime Builder | 플러그인 헤더·composer.json 파싱 → WordPress+MySQL+플러그인+역할별 계정 Docker 빌드, source_atlas·plugin_env 생성 | 빌드 성공률 90% 이상 |
| F2 | Stage 2 정적분석 | SAST로 취약점 후보 도출 + Codex(gpt-5.5) 2-pass 교차검증 → stage3_input.json 생성 | 오탐률 50% 이하 |
| F3 | Stage 3 PoC 생성 | 취약점 유형·컨텍스트로 RunPod LLM이 대상 맞춤 PoC 생성, 라이브 랩에서 실행 검증 | 자가 수정 3회 이내 성공 |
| F4 | Stage 4 Exploit | 격리 랩에서 PoC 실제 실행 + oracle 판정, 실패 피드백 재시도 및 공격 체인 분석 | 오탐률 50% 이하 |
| F5 | Stage 5 리포트 | Stage 4 결과를 DB에 적재 → 프론트가 CVSS·CWE·심각도·공격 결과·패치 렌더링 | 4시간 이내 보고서 생성 |
개념설계안
본 과제의 5단계 분석 파이프라인(정적분석 → 재검증 → PoC 생성 → Exploit 실행 → 리포트)은 모든 안에서 동일하다. "무엇을 하는가"는 고정되어 있으며, 변수는 "각 LLM 추론 단계를 어떤 인프라에서 실행할 것인가"이다. 이 결정은 비용 · 성능 · 보안 · 구현 부담을 동시에 좌우하므로, 팀 회의를 통해 LLM 인프라 구성을 축으로 3가지 후보안을 도출하였다. 3개 안 모두 프론트엔드(Vercel SPA), 백엔드 컨트롤러(FastAPI), 데이터베이스(PostgreSQL), Docker 샌드박스, 5단계 파이프라인 흐름은 공통으로 유지되며, 차이는 정적분석/PoC 생성/Exploit 생성 등 LLM 추론이 일어나는 위치에만 있다.
1안. Cloud-Only — 모든 LLM을 외부 API에 의존

모든 LLM 추론(정적분석, 재검증, PoC 생성, Exploit 생성)을 Anthropic Claude API 같은 외부 상용 LLM API로 위임하고, 백엔드는 AWS EC2 단일 인스턴스에서 오케스트레이션만 수행한다.
- 장점 : 인프라가 단순(GPU·vLLM·콜드스타트 부담 없음), 항상 상용 최신 LLM 사용으로 분석 품질이 가장 높음, 구현 부담 최소로 4개월 캡스톤 일정에 친화적.
- 단점 : 모든 단계에 토큰 비용 누적(특히 Exploit 코드 생성), 사용자 소스코드 전체가 외부 API로 전송되어 정보보호 이슈, 외부 API 장애·rate limit 변경 시 서비스 전체 영향.
2안. Hybrid — 외부 API + Local LLM 분담 (채택안)

정적분석 · 재검증은 외부 API로 처리해 정확도를 확보하고, 토큰 소비가 큰 PoC 생성은 RunPod GPU에서 호스팅하는 Local LLM이 담당한다. Exploit 코드 생성은 신뢰도가 높아야 하므로 외부 API를 이용한다. RunPod Serverless는 요청이 없을 때 Active Worker 0으로 유지되어 비용이 발생하지 않고 호출 시점에만 과금된다.
- 장점 : 토큰 비용이 큰 코드 생성 단계를 RunPod로 이전해 Cloud-Only 대비 월 운영비 50% 이상 절감, 검증·exploit 단계 원시 코드의 부분적 보안 격리, RunPod 자동 스케일링으로 유휴 시 GPU 비용 0.
- 단점 : 두 종류의 LLM 인프라를 모두 다뤄 구현 복잡도가 가장 높음, RunPod 콜드스타트 30초~2분 발생, 외부 API 의존이 완전히 제거되지는 않음.
3안. On-Premise — 모든 LLM을 자체 GPU에서 호스팅

AWS GPU 인스턴스(g5.xlarge, NVIDIA A10G 24GB)에 백엔드 + 모든 LLM + Docker 샌드박스 + Vector DB(ChromaDB)를 통합 배치하며 외부 API 호출은 0이다.
- 장점 : 외부 API 의존 완전 제거로 소스코드가 전혀 외부로 나가지 않음(보안 우위), 토큰 사용량과 무관한 고정 비용, 모델 교체·파인튜닝 등 모델 통제 가능.
- 단점 : Local LLM은 동급 외부 LLM 대비 코드 추론 정확도가 명확히 낮음(특히 PoC 생성), vLLM 배포·모델 가중치 관리·GPU 모니터링·장애 복구 등 운영 부담이 큼.
이론적 계산 및 시뮬레이션
소프트웨어 보안 과제 특성상 물리적 시뮬레이션 대신, 설계사양에서 정의한 6개 평가 항목과 가중치를 적용해 3개 개념설계안을 정량 평가하였다. 각 안에 1~5점(1: 매우 부족, 5: 매우 우수)을 부여하고 가중치를 곱해 종합 점수를 산출하였다(점수는 예측치).
| 평가 항목 (가중치) | 1안 Cloud-Only | 2안 Hybrid | 3안 On-Premise |
|---|---|---|---|
| 분석 정확도 (0.25) | 5 | 4 | 3 |
| 운영 비용 (0.20) | 2 | 4 | 1 |
| 응답 속도 (0.15) | 4 | 3 | 4 |
| 구현 가능성 (0.20) | 5 | 3 | 2 |
| 데이터 보안 (0.10) | 2 | 3 | 5 |
| 확장성 (0.10) | 5 | 4 | 2 |
| 종합 점수 | 3.85 | 3.55 | 2.65 |
채택 근거 : 종합 점수상 1안(3.85)이 1위이나, 1안은 운영 비용 2점(Stage 4 토큰 폭증 시 D 요구사항 "월 운영비 $50 이내" 충족 곤란)과 데이터 보안 2점(소스코드 전체 외부 송신)의 한계가 있고, 3안은 데이터 보안 최고점이나 비용 1점·구현 가능성 2점으로 학부 팀 역량 한계가 명확하다. 반면 2안은 단일 항목 1위는 없지만 모든 D 요구사항을 안정적으로 충족하는 유일한 안이다. RunPod Serverless 운영으로 월 운영비를 $38~55 수준으로 통제 가능하며, On-Premise(3안)보다 다룰 모델이 하나 줄어 구현 부담도 낮다. 캡스톤 환경에서 안정적 동작을 1차 목표로 하므로 단순 점수 1위 1안 대신 모든 D 요구사항을 충족하는 2안(Hybrid)을 최종 채택한다. 향후 사용량 증가 또는 데이터 보안 요구 강화 시 1안의 외부 API 의존을 3안 방향으로 점진 이전하는 발전 경로도 함께 고려한다.
상세설계 내용
시스템 아키텍처 (3계층 구조)

AutoPwn은 채택안(Hybrid)을 구체화한 3계층 구조로 설계한다.
- 프론트엔드 : Vanilla JS 기반 정적 SPA를 Vercel에 호스팅. Git 연동 자동 배포(CI/CD), 글로벌 CDN, 자동 HTTPS 제공. rewrite 프록시로 /api/* 요청을 EC2 백엔드로 연결.
- 백엔드 컨트롤러 : AWS EC2 단일 인스턴스(t2/t3.medium, vCPU 2 / RAM 4GB, Ubuntu 22.04 LTS)에서 FastAPI(uvicorn 8000)로 실행. 5개 라우터(인증, 프로젝트, 커뮤니티, 분석, 보고서)로 구성.
- GPU 추론 : 토큰 비용이 큰 Stage 3 PoC 코드 생성은 RunPod Serverless GPU(VRAM 24GB)에 vLLM으로 호스팅한 Qwen3.5-9B가 담당.
- 데이터 흐름 : 사용자 → Vercel → EC2 FastAPI 컨트롤러. ZIP 업로드는 Vercel Serverless의 4.5MB 페이로드 제한을 우회하기 위해 EC2 nginx 엔드포인트로 직접 전송되며, 메타데이터 API는 Vercel 프록시를 경유해 Mixed Content를 회피한다. 분석 시작 시 컨트롤러는 Stage 1~5를 순차 실행하고 각 단계 결과를 PostgreSQL에 저장하며, 프론트엔드는 GET /api/projects/{id}/status를 3초 주기로 폴링해 진행 단계를 실시간 반영한다.
세부기술 선택
- PoC 생성 모델 — Qwen3.5-9B : 호출 빈도·토큰 소비가 커 상용 API는 비용이 급증한다. 오픈 웨이트 모델을 RunPod에 직접 호스팅해 토큰 비용을 통제하고, 9B 규모는 단일 GPU에서 vLLM으로 구동 가능해 서버리스 환경의 메모리·기동 부담이 작다.
- 정적분석 모델 — Codex(gpt-5.5) : 대규모 코드베이스를 탐색·추론하는 에이전트형 코드 분석에 강점이 있어 플러그인 전체 구조 파악·취약점 후보 검증에 유리하다. Claude는 향후 단계별 대체·보강 옵션으로 둔다.
- GPU 추론 — RunPod Serverless : 요청이 없을 때 Active Worker 0으로 과금되지 않아 산발적 사용 패턴에 비용 효율이 높고, 폭증 시 자동 스케일로 대응한다.
- 백엔드 — FastAPI : 분석 파이프라인·LLM 연동·Docker 제어가 모두 Python으로 작성되어 일관성·유지보수성이 높고, async 지원으로 장시간 작업과 진행 폴링을 효율 처리한다.
- SAST + LLM 2-pass 교차검증 : SAST로 1차 후보를 도출하고 Codex(gpt-5.5)가 코드 컨텍스트와 함께 2-pass로 재검증해 두 방식이 서로의 약점(SAST 고오탐, LLM 미탐)을 보완하도록 했다.
- PHP AST 기반 컨텍스트 추출 : 정규식·grep 방식은 동적 PHP 코드의 엔드포인트·인증 구조를 정확히 파악하지 못하므로, PHP를 AST로 파싱해 엔드포인트·nonce·REST 인증·역할별 권한을 구조적으로 수집해 App Context를 구성한다.
데이터 모델 (ERD)

데이터베이스는 PostgreSQL 14를 사용하며, 핵심 6개 테이블과 진행 추적용 2개 테이블로 구성한다.
- 핵심 6개 : users(계정), projects(분석 대상 플러그인), vulnerabilities(취약점), reports(보고서 집계), posts · comments(취약점 정보 공유 커뮤니티).
- 진행 추적 2개 : analysis_runs, analysis_logs (세부 5단계 진행률·로그).
- 각 취약점에는 표준 분류 번호(CWE), 점수(CVSS), 위치(파일·줄 번호), 실제 공격 가능 여부가 함께 저장된다.
상태 전이

각 프로젝트는 5개 상태를 순서대로 거친다: 업로드 완료(UPLOADED) → 분석 중(ANALYZING) → 분석 완료(ANALYZED) → 검증 중(VERIFYING) → 검증 완료(VERIFIED). 사용자가 "분석" 버튼을 누르면 ANALYZING으로, Stage 1~3이 끝나면 ANALYZED로, "검증" 버튼을 누르면 VERIFYING으로 바뀌고, Stage 4가 실제 공격으로 성공·실패를 확정하면 VERIFIED로 마무리된다. 프론트엔드는 3초마다 상태를 폴링해 자동으로 다음 화면으로 전환한다.
5단계 분석 파이프라인 (소프트웨어 설계)
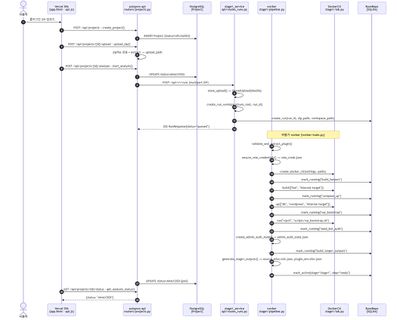
Stage 1 — WordPress 환경 빌드 시퀀스
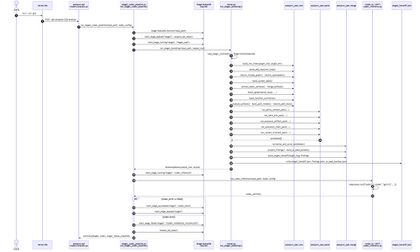
Stage 2 — 정적분석(SAST) 시퀀스
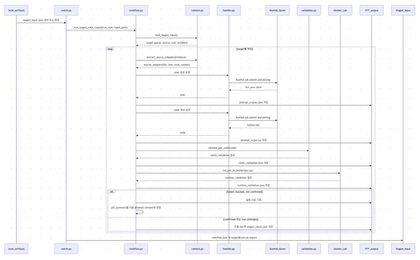
Stage 3 — PoC 자동 생성 시퀀스
- Autopwn fig seq stage4 5.jpg
Stage 4·5 — Exploit 실행·증거 수집 / 보고서 생성 시퀀스



컨트롤러는 POST /api/projects/{id}/analyze 호출 시 5단계를 순차 실행한다.
- Stage 1 — Runtime Builder : Docker Compose로 WordPress + MySQL + 플러그인 환경을 격리 빌드하고 source_atlas.min.json · plugin_env.slim.json 등 인벤토리를 산출한다.
- Stage 2 — 정적분석 : autopwn_sast CLI가 PHP 코드 그래프·taint 분석으로 취약점 후보(candidates.jsonl, findings.jsonl)를 도출하고, Codex(gpt-5.5)가 2-pass 교차검증해 stage3_input.json을 생성한다.
- Stage 3 — PoC 생성 : Qwen3.5-9B(vLLM, port 8001)로 후보별 PoC 파이썬 코드를 생성하고 구문·엔드포인트 포함 여부를 검증한 후 저장한다.
- Stage 4 — Exploit 실행 : 격리 샌드박스에서 PoC를 실제 실행해 EXPLOITABLE 여부와 증거(스크린샷·HTTP 트레이스)를 수집한다. Stage 4 Exploit 코드 생성·보강은 Codex CLI(GPT)가 담당한다.
- Stage 5 — 리포트 : 결과를 vulnerabilities · reports 테이블에 정규화 저장하고 프론트엔드가 보고서로 렌더링한다.
- 자가 복구 알고리즘 : Stage 1 빌드 실패 또는 Stage 3 PoC 검증(구문·엔드포인트 확인) 실패 시 컨트롤러가 실패 로그·스택트레이스를 LLM에 전달해 수정 패치를 받아 자동 재시도하며, 재시도 횟수는 단계별 최대 3회로 제한한다.
인프라 및 네트워크 구성
- PoC 지식 베이스(PoC_DB) : 1_seed(사람이 수집한 검증된 PoC)와 2_roughData(Stage 3 자동 생성 PoC)를 벡터 임베딩 검색 인덱스(RAG)로 연결하여, Stage 3 LLM이 새 PoC 생성 시 유사 과거 사례를 검색·주입해 정확도를 높인다.
- 도메인/DNS : 무료 동적 DNS인 DuckDNS로 autopwn.duckdns.org를 EC2 Public IP에 매핑하고, EC2 cron이 5분 주기로 갱신 API를 호출한다.
- HTTPS : nginx + Let's Encrypt 인증서로 443/TCP에서 TLS를 종단하고 내부적으로 FastAPI(127.0.0.1:8000)로 reverse proxy하며, certbot --deploy-hook으로 90일 만료 시 자동 갱신한다. /api/* 경로만 외부에 노출한다.
- 보안 : Security Group은 inbound 80/443만 개방하고 SSH(22)는 완전 차단하며, 운영 접근은 AWS SSM Session Manager로만 수행한다. outbound는 외부 LLM API · apt mirror · DuckDNS · Let's Encrypt · RunPod로만 허용해 측면 이동을 차단한다. OpenAI API 키는 systemd EnvironmentFile과 Docker secret으로 주입되어 평문 노출되지 않는다.
자재소요서 (Bill of Material)
| 번호 | 부품명 | 규격 | 용도 | 조달 |
|---|---|---|---|---|
| 1 | Vercel | SPA 호스팅 + Edge Network | 프론트엔드 정적 호스팅 및 메타데이터 API 프록시 | 구매 |
| 2 | AWS EC2 | t3.medium (vCPU 2, RAM 4GB) / Ubuntu 22.04 LTS | 백엔드 컨트롤러(FastAPI) 호스트 | 구매 |
| 3 | RunPod Serverless | GPU VRAM 24GB · Qwen3.5-9B (vLLM, bfloat16) | Stage 3 PoC 코드 생성 LLM 추론 (콜드스타트 30초~2분) | 구매(사용량 과금) |
| 4 | Codex CLI (GPT) | OpenAI GPT 기반 코드 생성 CLI | Stage 2 SAST AI 보강 및 Stage 4 Exploit 코드 생성·실행 | 구매 |
결과 및 평가
완료 작품의 소개
프로토타입 사진 혹은 작동 장면
주요 화면 (프로토타입)
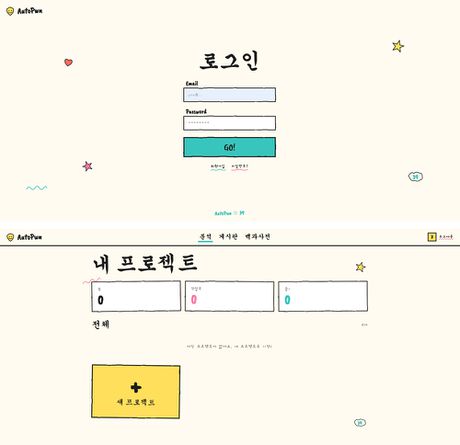
① 로그인 / ② 로비(내 프로젝트)
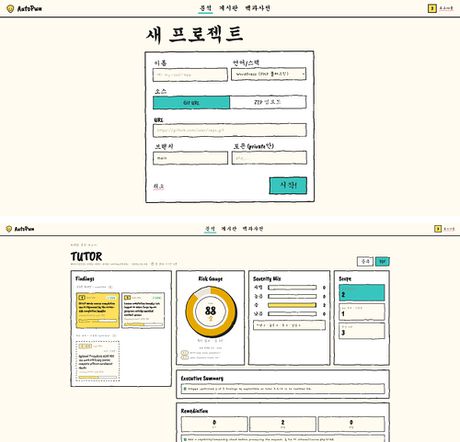
③ 코드 업로드 / ④ 코드 상세 페이지
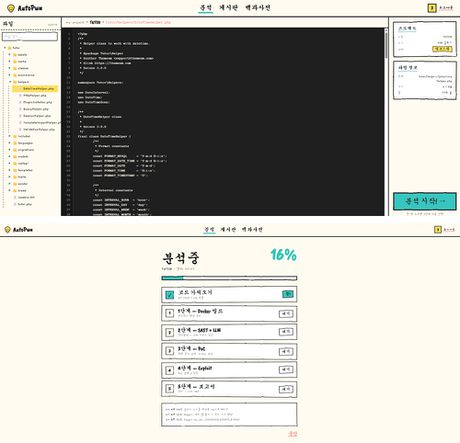
⑤ 분석 페이지 / ⑥ 보고서 페이지



작동 장면 (실행 순서)
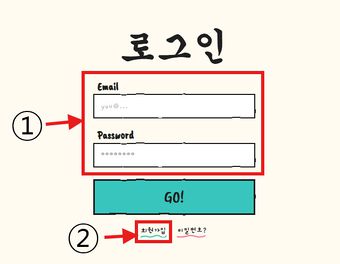
① 로그인
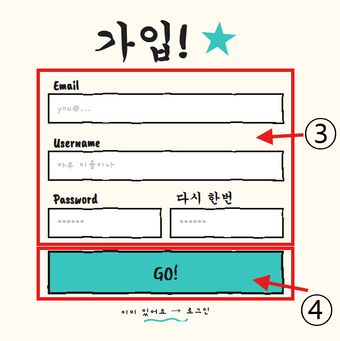
② 회원가입 (계정 생성)
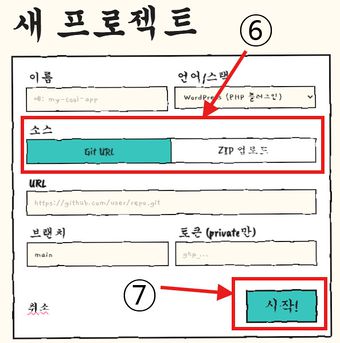
③ 새 프로젝트 — 플러그인 ZIP/Git URL 업로드

④ 5단계 자동 실행 — 진행률·라이브 로그




- 업로드 : 회원가입/로그인 후 "새 프로젝트"에서 분석 대상 WordPress 플러그인을 ZIP 또는 Git URL로 업로드하고 시작 버튼을 누른다(현재 지원 대상은 WordPress/PHP 플러그인).
- 코드 확인 : 업로드된 파일 트리와 소스를 검토한 뒤 "분석 시작" 버튼을 누른다.
- 자동 실행 : 컨트롤러가 5단계를 백그라운드로 자동 실행하고, 진행 화면이 현재 단계 · 진행률 · 라이브 로그를 실시간 표시한다.
- 진행 순서 : Stage 1 랩 빌드 → Stage 2 SAST+Codex 교차검증 → Stage 3 RunPod PoC 생성·실행 → Stage 4 Exploit + oracle 판정 → Stage 5 보고서.
- 결과 확인 : 분석이 끝나면 프로젝트 상태가 "검증 완료"로 바뀌고, 취약점 목록 · 심각도 · 위험도 점수 · 실제 공격 결과 · 패치 제안이 보고서 화면에 표시된다.
실제 공개 플러그인(user-registration)으로 전 구간을 검증하여 취약점 탐지부터 보고서 적재까지 정상 동작을 확인하였으며, 비-WordPress 등 분석이 불가능한 입력은 해당 단계에서 실패 사유와 함께 표시된다.
포스터
완료작품 포스터는 별도 이미지 파일로 업로드 예정이다. 포스터 이미지를 위키에 올린 뒤 아래 자리표시자를 실제 태그로 교체한다.
관련사업비 내역서
| 항목 (품명, 규격) | 수량 | 단가 | 금액(천원) | 비고 |
|---|---|---|---|---|
| Claude Pro Subscription | 3 | $20 | 94.699 | 결제일 환율 변동 |
| Claude Extra Usage | 1 | $70 | 110.951 | - |
| Vercel Pro Subscription | 1 | $82 | 125.974 | 6월분 추가 지출 $60 |
| Runpod Prepay for usage | 1 | $30 | 48.325 | - |
| ChatGPT Pro (for Codex) Subscription | 1 | - | 144.545 | - |
| 회의비 | 1 | - | 120.000 | - |
| 합계 | 644.494 |
- 달러 변동성에 의해 단가는 미국 달러(USD)로 표기.
- Vercel 6월 사용량에 따른 추가 지출 $60 반영(2026.6.9 기준 $1 = ₩1,528.6).
- 학교 부담금 600천원 / 과제팀 부담금 0원 기준이며, 합계 644.494천원은 6월 추가 사용분이 반영된 정산액이다.
완료작품의 평가
평가 항목별 결과
| 평가 항목 | 평가 방법 | 적용 기준 / 개발 목표치 | 비중(%) |
|---|---|---|---|
| Stage 1 검사 환경 자동 구축 | 플러그인 파일 1개를 넣어 가상 웹사이트(웹+DB)가 자동 기동·플러그인 작동·구조 요약 생성 여부 확인 | 서로 다른 플러그인 5개 중 4개 이상 사람 개입 없이 구축 | 22.5 |
| Stage 2 탐지 신뢰도 (다층 취약점 분석) | 1차(환경구축)→2차(SAST)→3차(SAST+LLM) 탐지/분석 파이프라인 동작 및 후보별 근거 확인 | 탐지 근거·영향 파일·수정 권장 고지, 등급(치명/높음/중/낮음) 부여, FP율 50% 미만 | 7.5 |
| Stage 3-1 PoC 생성 능력 | 취약점 종류에 맞는 WordPress 전용 공격 요령을 자동 선택·주입하는지 확인 | 올바른 요령 선택 정확도 90% 이상 | 12.0 |
| Stage 3-2 PoC 자동 생성 및 검증 | 코드 생성 → 문법 자동검사 → 가상 사이트 시험 실행 → 실패 시 재생성(최대 3회) 흐름 확인 | 생성 코드 문법 검사 통과율 80% 이상 + 재생성 루프 정상 작동 | 8.0 |
| Stage 4 영향 검증 (증거 완성도) | 격리 가상 사이트에서 실제 공격을 시도해 성공/부분/실패 판정, 성공 건의 증거(통신 기록·DB 변화 등) 수집 | 결과 판정 + '성공(Exploitable)' 건은 반드시 증거 첨부 | 25.0 |
| Stage 5 리포트/시각화 완성도 | 생성된 보고서를 열어 핵심 항목이 모두 있고 빈칸이 없는지 확인 | 요약·상세·우선순위·패치방법 5종 + 취약점별 근거(영향 코드·시연 코드·증거) 채움, 빈칸 0 | 25.0 |
실제 취약점 발견 및 CVE 등록 실적
본 서비스를 실제 운영 중인 오픈소스(WordPress 플러그인 및 Chamilo LMS)에 적용하여, 테스터가 AutoPwn을 활용해 다수의 실제 취약점을 발견하였다. 그 결과 신규 취약점에 대해 CVE가 공식 발급되고 버그 바운티 총 $6,815를 수령하였다. 이는 합성 데이터 기반 내부 지표를 넘어, 실제 소프트웨어에서 미공개 취약점을 탐지·실증할 수 있음을 보여주는 결과이다.
| 구분 | 건수 |
|---|---|
| CVE 발급 및 바운티 지급 | 13건 |
| 중복 | 16건 |
| vendor 직접 제보 (CVE 미발급) | 7건 |
대표 성과
- Kirki (≤6.0.6) — 비인증 권한 상승, CVE-2026-8206, 바운티 $6,436
- Chamilo LMS (2.0 RC2) — eval()을 통한 원격 코드 실행(RCE), CVE-2026-33618
- Quiz Maker (≤6.7.1.20) — 비인증 저장형 XSS, CVE-2026-6817, 바운티 $120
- User Registration & Membership (≤5.1.5) — PayPal 결제 우회, SQL Injection, 바운티 $259
- 단일 제품인 Chamilo LMS에서만 CVE 10건을 발견하여 분석 깊이를 입증.
대표 성과 13건 상세
| 제품 | 버전 | 취약점 | CVE-2026- | 바운티 |
|---|---|---|---|---|
| Kirki | ≤6.0.6 | 비인증 권한 상승 | 8206 | $6,436 |
| Quiz Maker (AYS) | ≤6.7.1.20 | 비인증 저장형 XSS | 6817 | $120 |
| Chamilo LMS | 2.0 RC2 | eval() 원격 코드 실행(RCE) | 33618 | - |
| Chamilo LMS | ≤2.0 RC2 | 안전하지 않은 직접 객체 참조(IDOR) | 33736 | - |
| Chamilo LMS | ≤2.0 RC2 | XML 외부 개체(XXE) 주입 | 33737 | - |
| Chamilo LMS | ≤2.0 RC2 | API 역할 변경을 통한 권한 상승 | 40291 | - |
| Chamilo LMS | ≤1.11.36 | BigUpload 인증된 임의 파일 쓰기 | 33704 | - |
| Chamilo LMS | ≤1.11.36 | Twig 템플릿 소스 비인증 노출 | 33705 | - |
| Chamilo LMS | ≤1.11.36 | REST API 자가 권한 상승(학생→교사) | 33706 | - |
| Chamilo LMS | ≤1.11.36 | 취약한 비밀번호 복구 메커니즘 | 33707 | - |
| Chamilo LMS | ≤1.11.36 | REST API 개인정보(PII) 노출 | 33708 | - |
| Chamilo LMS | ≤1.11.36 | 예측 가능한 REST API 키 생성 | 33710 | - |
| User Registration & Membership | ≤5.1.5 | PayPal 결제 우회, SQL Injection | 대기 중 | $259 |
중복 제보 16건 상세
| 제품 | 버전 | 취약점 |
|---|---|---|
| Kirki | ≤6.0.9 | 자격증명/비밀값 노출 |
| TrueBooker | ≤1.2.1 | 관리자 계정 탈취 |
| Quotes llama | ≤3.1.3 | SQL Injection |
| Frontend File Manager | ≤23.6 | 임의 파일 삭제 |
| Booster for Woocommerce | ≤8.0.0 | 임의 파일 업로드를 통한 원격 코드 실행 |
| Dokan | ≤5.0.0 | 관리자 권한으로의 상승 |
| LearnPress | ≤4.3.6 | 보호된 콘텐츠 노출 |
| Everest Forms | ≤3.4.4 | 임의 파일 읽기 |
| Survey Marker | ≤5.2.1.4 | 저장형 XSS |
| WPForms | ≤10.9.1 | 취약한 접근 제어 |
| Tutor LMS | ≤3.9.10 | 안전하지 않은 직접 객체 참조(IDOR) |
| Starter Templates | ≤4.4.52 | DNS rebinding을 통한 서버 측 요청 위조(SSRF) |
| Lifter LMS | ≤9.2.1 | CSRF를 통한 임의 강의 등록 / 안전하지 않은 직접 객체 참조(IDOR) |
| Import WP | ≤2.14.21 | 저장형 XSS |
| NinjaForms | ≤3.14.4 | 취약한 접근 제어 |
향후계획
한계점 (어려웠던 내용)
- 랩 재현이 가능한 플러그인만 서비스 대상이다. 외부 SaaS, 위탁 결제, 특수 의존성이 필요하면 자동 익스플로잇이 불가능하다.
- LLM의 비결정성 문제. 같은 입력도 run마다 결과가 달라질 수 있어 결정적 도구보다 재현성·일관성이 낮다.
- 타깃이 많으면 Stage 4의 제한 시간 내에 다 돌지 못하고 GPT-5.5 API 비용이 매우 커진다(예산 부족으로 검증이 실패한 경우 있음).
- DB·파일·응답 변화로 확인되는 취약점만 confirmed 되고, 미묘한 로직 부작용·타이밍은 오라클이 없어 검증되지 않는다.
- 미탐(False Negative) 측정 불가 문제. Recall을 잴 ground truth가 없어 known-CVE로만 검증할 수 있고 전부 찾았다는 보장은 불가능하다.
- 특정 WP/PHP/DB 버전 조합, 멀티사이트, 버전별 차이, 특수 설정은 커버에 제한이 있다.
차후 구현할 내용
- 사용자별 산출물 저장 시 암호화(at-rest)를 완성한다(현재는 데모 단일 네임스페이스에서 평문 동작).
- 긴 분석 동안 분석 랩이 만료 정리되지 않도록 lease 갱신·정리 정책을 정교화한다.
- 보고서의 공격 체인 시각화와 PDF 내보내기를 고도화하고, 취약점 0건 등 예외 케이스 표시를 보완한다.
- 분석 대상을 WordPress 외 다른 PHP 프레임워크·언어로 확대한다.
- RAG 지식 베이스(CVE/PoC 문서)를 확충·고도화하여 유의미한 RAG를 구성한다.
특허 출원 내용
해당 없음. (본 과제는 별도 특허 출원을 진행하지 않았다. 특허 가능 요소 및 선행 특허 분석은 2.2.1 관련 기술의 현황 및 분석의 특허조사 항목을 참조.)