"1조"의 두 판 사이의 차이
(→구성원 소개) |
Uoscivil202521 (토론 | 기여) (→관련 기술의 현황) |
||
| (사용자 4명의 중간 판 146개는 보이지 않습니다) | |||
| 1번째 줄: | 1번째 줄: | ||
| + | |||
<div>__TOC__</div> | <div>__TOC__</div> | ||
==프로젝트 개요== | ==프로젝트 개요== | ||
=== 기술개발 과제 === | === 기술개발 과제 === | ||
| − | ''' 국문 : ''' | + | ''' 국문 : ''' 재활용 소재, 폐기물을 사용한 경제적, 친환경 콘크리트 연구 |
| − | ''' 영문 : ''' | + | ''' 영문 : ''' Recycled and Eco-friendly Concrete Research |
===과제 팀명=== | ===과제 팀명=== | ||
| 11번째 줄: | 12번째 줄: | ||
===지도교수=== | ===지도교수=== | ||
| − | + | 김지수 교수님 | |
===개발기간=== | ===개발기간=== | ||
| − | + | 2025년 9월 ~ 2025년 12월 (총 4개월) | |
===구성원 소개=== | ===구성원 소개=== | ||
| − | 서울시립대학교 | + | 서울시립대학교 토목공학과 2020860047 최효광(팀장) |
| − | 서울시립대학교 | + | 서울시립대학교 토목공학과 2020860009 김민혁 |
| − | 서울시립대학교 | + | 서울시립대학교 토목공학과 2020860031 이정우 |
| − | 서울시립대학교 | + | 서울시립대학교 토목공학과 2020860033 조현진 |
| + | |||
| + | ==서론== | ||
| + | ===개발 과제의 개요=== | ||
| + | ====개발 과제 요약==== | ||
| + | 본 과제에서는 꾸준히 증가하는 폐기물 처리를 위해 플라스틱 필렛, 물티슈를 대체제로 적용하여 제작 단가를 낮추고 탄소 배출을 줄이면서도 우수한 강도와 내구성을 확보하는 공법을 연구한다. 이를 통해 건설 산업의 자원 순환과 탄소중립 실현에 기여할 수 있는 지속 가능한 건설재료 기술을 제시하고자 한다. | ||
| + | |||
| + | ◇ 목표 | ||
| + | - 폐기물과 재활용 소재를 활용해 경제성 및 친환경성을 갖춘 콘크리트 개발 | ||
| − | + | ◇ 방법 | |
| + | - 플라스틱 필렛, 물티슈를 골재 대채제 및 첨가제로 활용 | ||
| − | + | ◇ 핵심성과 | |
| + | - 제작 단가 절감 | ||
| + | - 탄소 배출 감소 | ||
| + | - 강도 및 내구성 확보 | ||
| − | = | + | ====개발 과제의 배경==== |
| − | ===개발 과제의 | ||
| − | + | ◇ 폐기물 처리 문제 | |
| + | - 2026년부터 수도권 3개 시도 생활폐기물 직매립 전면금지 | ||
| + | - 새로운 폐기물 자원화 기술 개발 필요성 증가 | ||
| + | |||
| − | - | + | ◇ 원자재 가격 상승 |
| + | - 건설 자재 대부분을 수입에 의존하여 가격 불안정성 증가 | ||
| + | - 최근 고환율이 지속되어 건설자재 비용 부담 | ||
| − | - | + | ◇ 탄소 중립 트렌드 |
| + | - 글로벌 탄소 배출 감축 요구 강화와 ESG 경영의 확산 | ||
| + | - 탄소 저감 기술 개발 필요성 및 친환경 건설 자재 개발 중요성 증가 | ||
| − | - | + | ====개발 과제의 목표 및 내용==== |
| + | ◇ 성능 목표 | ||
| + | - 기존 콘크리트 대비 70% 이상 강도 확보 | ||
| − | - | + | ◇ 경제 목표 |
| + | - 제작 원가 20% 절감 | ||
| + | - 경제성 분석을 통해 사회적 비용 절감 | ||
| + | |||
| + | ◇ 환경목표 | ||
| + | - 탄소 배출량 감소 | ||
| + | - 폐기물 처리 및 재활용률 향상 | ||
===관련 기술의 현황=== | ===관련 기술의 현황=== | ||
====관련 기술의 현황 및 분석(State of art)==== | ====관련 기술의 현황 및 분석(State of art)==== | ||
| + | *전 세계적인 기술현황 | ||
| + | 전 세계적으로 탄소 중립 및 지속 가능한 건설기술 관련 연구 및 개발이 활발하다. 그중 본 과제와 관련 있는 폐기물·재활용 골재 활용 콘크리트 기술의 최신 동향과 연구 성과는 다음과 같다 | ||
| − | + | '''Foti, D. (2012) | |
| + | :PET 병을 절단하여 제작한 섬유로 보강한 콘크리트 공시체에 대해 연구를 진행. 콘크리트의 연성이 향상. 콘크리트와 PET 사이의 부착 성능이 우수하다는 결과''' | ||
| − | + | '''Kim, Byung-Chul et al. (2015) | |
| + | : LCD 폐유리 미분말을 사용하여 고강도 콘크리트에 대한 연구를 진행. 대부분의 경우 강도가 저하되었으나 미분말의 입도 및 입경을 균질하게 한다면 강도가 향상될 것으로 평가''' | ||
| − | + | '''Toghroli, A. et al. (2018) | |
| + | :재활용 분쇄 유리, 강섬유, 폐타이어, 플라스틱 등의 폐기물을 이용한 포장용 포러스 콘크리트에 대해 연구시멘트 사용을 줄이고 폐기물 문제를 완화하는 효과 확인''' | ||
| − | + | '''Babafemi, A. et al. (2018) | |
| + | :폐플라스틱을 혼입하여 제작한 콘크리트의 기계적 특성과 내구성에 대해 연구. 압축강도, 휨강도 등의 특성들은 전반적으로 감소하였으나 공학적 요구를 충족, 폐플라스틱의 전처리 방법에 대해 추가 연구의 필요성을 제시''' | ||
| − | + | '''Yang, I.-H. (2021) | |
| + | :플라스틱 재활용 섬유를 콘크리트 제작에 사용하여 균열저항성 및 인장강도의 개선확인 | ||
| + | ''' | ||
| − | + | '''Deng, J.-X. et al. (2023) | |
| + | :재활용 골재, 볏짚, 유약 처리한 구슬 등을 이용하여 재활용 단열 콘크리트를 개발. 기계적 성능 기준을 충족하면서 우수한 단열 성능을 제공하는 최적 배합비를 도출 | ||
| + | ''' | ||
| − | + | '''Woo, G.-S., Kim, J.-H. (2024) | |
| + | :30~40MPa 이상의 순환골재 콘크리트 제조를 위한 실험적 연구를 진행. 해당 연구에서는 순환골재의 품질 개선 및 강도 증진을 위한 기초자료를 제공하여 순환골재 콘크리트의 폭넓은 활용을 도모''' | ||
| − | + | *특허조사 및 특허 전략 분석 | |
| − | + | '''폐도자기와 폐애자를 경량 골재 대체재와 포장용 골재로 사용하는 재활용법''' | |
| − | + | :폐애자를 가능한 구에 가깝도록 파쇄, 연마하여 정형한 것을 천연 자갈을 대체할 수 있는 골재(상품명: 리포세라)로 사용. 아스팔트 포장의 노반 하층부의 쇄석의 일부로 사용. 골재에 열경화성 합성수지를 바인더로 사용하여 아스팔트 포장의 표층용 골재로 사용한다. | |
| − | + | '''유리병컬럿을 경량 골재 대체재와 포장용 골재로 사용하는 재활용법''' | |
| − | + | :빈 병의 컬럿을 천연 모래의 경량골재 대체재나 컬러 투수 포장용 골재 등으로 사용하는 재활용법. 컬릿은 파쇄된 입체형의 입자로서 모서리각이 예리하여 위험성이 많으므로 새로 발명한 시스템을 적용 | |
| − | + | '''재활용 경량 복합 단열골재''' | |
| + | :스치로폴 발포체가 갖는 물성 중 단열성을 유지하면서 여러 강도를 증진시킬 수 있는 방법 관한 것. 강도, 색상, 모양, 크기 등도 다양하며 방습, 투습, 내부식성 또한 우수. 재활용 원료를 사용하므로 원료비 및 작업비용도 크게 절감 | ||
| + | '''Recycled Plastic Aggregate for use in Concrete (US10294155B2)''' | ||
| + | :폐플라스틱을 입자화해 콘크리트용 골재로 사용. 입자 크기 및 형상을 제어하여 시멘트와의 부착력을 개선 | ||
| + | '''Method for producing concrete using recycled plastic (WO2020000106A1)''' | ||
| + | :폐플라스틱을 골재로 활용한 단열 콘크리트 제조 공정. 플라스틱 골재에 시멘트 및 모래를 코팅하여 콘크리트 혼합물과의 부착력을 높이고 균일하게 혼합 | ||
====시장상황에 대한 분석==== | ====시장상황에 대한 분석==== | ||
| − | |||
| − | |||
| − | |||
| − | + | '''부산항만공사(BPA)''' | |
| + | :케이슨 속채움재로 순환골재를 사용해 약 25억 원의 예산 절감 효과, 이산화탄소 배출 저감을 통한 약 121억 원 규모의 경제적, 환경적 편익을 창출 | ||
| − | + | '''롯데건설''' | |
| + | :시멘트를 5%만 사용하고도 기존 대비 동등 이상의 강도를 발현하는 '저탄소 수화열 저감 콘크리트'개발, '고로 슬래그’가 80% 이상 포함, 첨가제가 일부 사용,고로 슬래그는 시멘트에 비해 탄소 배출량은 10분의 1, 가격은 시멘트의 70% 수준. | ||
| − | + | '''대우건설''' | |
| + | :자체 개발 저탄소 콘크리트를 아파트 전체 공사로 확대한다는 계획, 기존 대비 시멘트 사용량과 이산화탄소 배출량을 절반 넘게 줄이면서 강도 지연과 품질 하자 문제를 해소 | ||
| − | + | '''포스코 이앤씨''' | |
| − | + | :저탄소 초고강도 콘크리트 파일 개발, 시멘트 대신 무수석고와 제철슬래그를 배합해 이산화탄소 발생량을 4% 수준으로 절감, 강도가 기존 파일보다 높아 시공 수량을 줄일 수 있어 공사 기간 단축과 원가 절감 가능 | |
| − | |||
| − | |||
| − | + | '''삼성물산 건설부문''' | |
| − | + | :콘크리트 생산 과정에 이산화탄소를 주입해 화학적 반응을 일으켜 콘크리트 강도를 높이는 기술을 확보, 시멘트 사용량과 비용 절감 가능, 이산화탄소가 콘크리트 내부에 저장되기 때문에 탄소 배출량이 70% 가까이 줄어드는 효과 | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
===개발과제의 기대효과=== | ===개발과제의 기대효과=== | ||
| − | + | ====기술적 기대효과==== | |
| + | - 재활용으로 건설 자재의 원료 다양성 확대 | ||
| + | - 재료에 따른 콘크리트의 강도, 내구성 등 특성 변화 파악 가능 | ||
| + | - 폐기물 전처리 방식에 따라 접착력, 공극률 등이 달라지므로 최적 조건 도출 가능 | ||
| + | - 경량화, 단열성 등 특정 성능을 개선 가능 | ||
| + | - 요구 특성에 따른 맞춤형 콘크리트 제작 가능 | ||
| + | ====경제적, 사회적 기대 및 파급효과==== | ||
| − | + | - 건설 재료의 가격이 상승하는 상황에서 원가 절감 가능 | |
| + | - 시공 수량을 줄여 공사 기간 단축 가능 | ||
| + | - 산업 및 생활폐기물의 처리 비용 절감, 지자체 및 기업의 부담 완화 | ||
| + | - 폐기물 처리 문제를 일부 해결, 생산 과정의 탄소 배출량 감소 가능 | ||
| + | - 환경 보호 및 친환경 건설 기술 실현에 기여 | ||
| − | + | ===기술개발 일정 및 추진체계=== | |
| + | ====개발 일정==== | ||
| + | [[파일:개발일정.png]] | ||
| − | + | ====구성원 및 추진체계==== | |
| + | 건설순환 재료학회, 콘크리트 학회지 자료를 참조한 다양한 배합의 공시체를 시험하여 최적의 배합을 찾는 과정을 반복합니다. | ||
==설계== | ==설계== | ||
===설계사양=== | ===설계사양=== | ||
====제품의 요구사항==== | ====제품의 요구사항==== | ||
| − | + | [[파일:2020860037_요구사항.png]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
====설계 사양==== | ====설계 사양==== | ||
| + | [[파일:2020860037_설계사항.png]] | ||
| − | + | ===개념설계안=== | |
| + | [[파일:2020860037_개념설계.png]] | ||
| − | |||
| − | |||
| − | + | 배합비 | |
| + | 물:시멘트:잔골재=1:2:4.8 | ||
| − | + | 필렛량 | |
| + | 잔골재 무게의 15% | ||
| − | + | 물티슈량 | |
| + | 공시체 부피의 0%, 1%, 2%, 4% | ||
| − | + | ===상세설계 내용=== | |
| + | 배합비 | ||
| − | + | 기본 공시체 | |
| + | [[파일:2020860037_기본.png]] | ||
| − | + | 플라스틱 필렛 포함 공시체 | |
| − | + | [[파일:2020860037_필렛.png]] | |
| − | [[파일: | ||
| − | + | 물티슈량 | |
| + | [[파일:2020860037_물티슈.png]] | ||
| − | + | ||
| − | |||
| − | |||
| − | + | 일축압축강도 시험 | |
| + | 기본공시체 6개와 필렛을 넣고 물티슈를 다르게 넣은 공시체 각각 6개씩 총 30개의 공시체를 제작한다. | ||
| + | 각각의 공시체 중 5개를 선정해 일축압축강도 시험을 실시하고 그 값을 정리한다. | ||
| + | [[파일:2020860037_압실.png]] | ||
| − | + | 휨강도 실험 | |
| − | + | 일축압축강도와 같은 배합으로 각각 3개씩 총 15개의 공시체를 제작한다. | |
| − | [[파일: | + | [[파일:2020860037_휨실.png]] |
| − | |||
| − | |||
| − | |||
| − | |||
| + | ==결과 및 평가== | ||
| + | '''실험결과''' | ||
| + | 일축압축강도 | ||
| + | [[파일:2020860037_압표.png]] | ||
| + | [[파일:2020860037_압그.png]] | ||
| − | [[파일: | + | 휨강도 실험 |
| + | [[파일:2020860037_휨표.png]] | ||
| + | [[파일:2020860037_휨그.png]] | ||
| + | '''평가''' | ||
| + | 환경성 평가 | ||
| + | [[파일:2020860037_환식.png]] | ||
| + | [[파일:2020860037_환그.png]] | ||
| + | -공시체 6개 제작 과정에서 사용된 폐플라스틱–섬유의 질량을 기준으로 환경적 편익을 산정하였다. 분석 결과, 공시체 6개를 제작하는 과정에서 약 26g CO₂의 온실가스 배출 저감 효과가 확인되었다. 이는 동일한 양의 폐플라스틱을 매립 처리했을 때 발생하는 온실가스 배출을 재활용을 통해 직접적으로 차단한 효과에 해당한다. | ||
| + | -특히 폐기물의 매립은 분해 과정에서 장기적인 온실가스 배출을 야기하는데, 본 연구의 재활용 방식은 이러한 배출원을 근본적으로 감소시키는 결과를 초래한다. 비록 개별 실험 단위에서는 수 g 단위의 저감 효과로 나타났지만, 이는 대량 생산 시 누적 효과가 기하급수적으로 커진다는 점에서 환경적 가치가 크다. | ||
| + | -예컨대 동일한 배합을 산업 규모로 확대할 경우, 수백 kg에서 수 톤 단위까지 CO₂ 절감이 가능해져 건설 산업의 온실가스 감축에 실질적으로 기여할 잠재력을 지닌다. | ||
| + | 종합적으로, 폐플라스틱 활용 콘크리트는 폐기물 매립을 감소시키는 동시에 온실가스 배출을 줄임으로써 높은 환경성 개선 효과를 보였으며, 이는 본 연구의 환경성 개발 목표(폐기물 감량 및 CO₂ 배출 저감)를 충분히 충족하는 것으로 평가된다. | ||
| − | + | 경제성 평가 | |
| − | + | [[파일:2020860037_경식.png]] | |
| − | + | [[파일:2020860037_경그.png]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [[파일: | ||
| − | |||
| − | |||
| − | |||
| − | [[파일: | ||
| − | |||
| − | + | -공시체 6개 제작 과정에서 사용된 폐플라스틱–섬유의 질량을 기준으로 경제적 편익을 산정하였다. 분석결과 우선 재료비 측면에서, 폐플라스틱을 골재로 치환함으로써 약 3.09원의 골재 비용 절감이 발생하였으며, 동일한 양의 폐기물을 매립하지 않음에 따라 약 90원의 폐기물 처리비 절감 효과가 추가로 발생하였다. | |
| + | -다만 폐기물을 재료로 활용하기 위해 반드시 필요한 전처리 과정에서 약 164원의 추가 비용이 발생하는 것으로 확인되었다. 약 70원 정도의 가격이 증가되어, 오히려 사용하지 않을 때 경제적 이점이 있는 것으로 나타났다. | ||
| + | -폐플라스틱의 전처리 과정과 기업들의 친환경 사업 확대, 유가 상승에 의한 플라스틱 가격 상승이 폐플라스틱 필렛의 가격 상승의 요인으로 판단된다. | ||
| − | + | 강도 평가 | |
| + | [[파일:2020860037_평일.png]] | ||
| + | [[파일:2020860037_평휨.png]] | ||
| − | + | -혼입률이 증가함에 따라 압축강도는 전반적으로 감소하는 경향을 보였으며, 그중 4% 혼입 배합의 28일 추정 압축강도는 20.6 MPa로 나타났다. 이는 기준 콘크리트 대비 약 65.8% 수준으로, 본 연구의 주목적이었던 기준 콘크리트 강도 대비 70% 확보에는 미치지 못하였다. 또한 휨강도는 대부분이 기존 콘크리트 강도 대비 70% 이하의 수치를 나타냈다. 즉, 구조용 콘크리트 수준의 성능을 확보하는 데에는 한계가 있는 것으로 평가되었다. | |
| − | + | -그러나 재활용 콘크리트의 활용은 반드시 구조용 용도에만 한정되는 것은 아니다. 이에 따라 본 연구에서는 두 번째 목표로 비구조용 포장재(보도블록·조경 블록 등)로의 활용 가능성을 평가하였다. 이를 위해 일반적으로 산업 현장에서 사용되는 기능적 최소 기준인 압축강도 20 MPa 이상, 휨강도 3 MPa 이상을 적용하였다. | |
| − | + | -4% 혼입 배합의 압축강도는 20.6 MPa로 이 기준을 충족하였으며, 휨강도 역시 평균 4.41 MPa로 나타나 비구조용 포장재 적용 기준인 3 MPa을 충분히 상회하였다. 또한 KS F 4419 보도블록 규격의 최저 휨강도 기준(3.5 MPa) 역시 충족하는 것으로 확인되었다. 다만 KS 규격의 평균강도 기준(5.0 MPa)에는 조금 부족한 수치를 보였다. | |
| − | + | ===완료 작품의 소개=== | |
| − | + | ====포스터==== | |
| − | + | [[파일:SOC종합설계_포스터_1조(최효광).pdf]] | |
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | - | ||
| − | |||
| − | |||
| − | |||
| − | - | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | [[파일: | ||
| − | |||
| − | |||
| − | [[파일: | + | ===완료작품의 평가=== |
| + | [[파일:2020860037_최.png]] | ||
| + | -평가 결과 환경성 면에서는 물티슈 4% 혼입된 배합이 유리하나 강도 면에서 실제 현장에서 사용되기에 무리가 있다. 따라서, 경제성을 제외한 평가에서 준수한 결과를 얻은 물티슈 2% 혼입된 배합을 최적 배합비로 선정했다. | ||
| − | |||
| − | - | + | -본 과제에서 개발된 재활용 폐기물 콘크리트는 강도, 환경성, 경제성을 종합적으로 분석한 결과, 추가적인 연구를 통한 상용화 가능성이 확인되었다. 건설 산업에서의 자원 순환형 콘크리트로 발전할 잠재력이 높다고 판단하였다. |
| + | -본 과제의 재활용 콘크리트는 강도 측면에서 기존 구조용 콘크리트의 표준 압축강도 기준과 비교했을 때 일부 조건에서는 적용에 제한이 있을 수 있다. 하지만 비구조용 콘크리트, 보도 블럭, 도로용 콘크리트 등 저하중 환경에서 충분한 활용이 가능한 성능을 확보하였다. 실제 국내 도로 포장용 콘크리트 및 보도재 기준과 비교했을 때, 본 연구에서 제조된 시편은 기준 강도를 충족하거나 근접한 수준을 나타냈으며, 이는 초기 상용화를 위한 적용 분야가 명확히 존재함을 의미한다. | ||
| + | -제조 과정에서 사용된 폐기물 재료의 형상적 특성 중 플라스틱 필렛의 큰 크기, 매끄러운 표면 등은 콘크리트 내부에서 결합력 감소 및 미세 균열의 원인으로 작용한 것으로 판단된다. 따라서 향후 연구에서 재활용 재료의 표면 거칠기 증가 처리, 필렛 크기 최적화 등을 연구할 경우, 강도가 현재 수준보다 향상될 것으로 예상된다. 이를 통해 장기적으로는 구조용 콘크리트의 강도 수준을 확보할 수 있을 것으로 기대된다. | ||
| + | -환경성 측면에서도 본 재활용 콘크리트는 의미있는 결과를 보였다. 폐기물 기반 재료 활용은 매립량 및 탄소 배출량 감소, 자원 재활용률 증대라는 효과를 가져온다. 이는 국내·외 건설 산업에서 요구되고있는 ESG 정책 및 탄소중립 목표와 방향성이 일치한다. 특히, 정부·지자체의 순환자원 의무 사용 정책, 녹색건축 인증제도와 연계될 경우 시장 확장성이 매우 크다. | ||
| + | -경제성 측면에서는 재활용 폐기물로 대체하면 비용이 증가되는 결과가 나타났다. 하지만 폐기물 전처리 공정이 대규모로 구축된다면 폐기물 전처리에 드는 비용이 감소하여 비용이 감소할 것으로 예상된다. | ||
| + | -따라서 본 연구과제는 기술적 완성도 향상과 규격화 작업을 지속한다면, 향후 지속 가능한 건설 산업과 친환경 콘크리트 시장 확대에 중요한 역할을 수행할 수 있을 것으로 예상된다. | ||
| − | + | ===참고 문헌=== | |
| − | - | + | Yang, I.-H. (2021). Manufacturing and characteristics of recycled plastic fiberreinforced concrete. Magazine of RCR, 16(1), 17–22. https://doi.org/10.14190/MRCR.2021.16.1.017 |
| − | + | Kim, Byung-Chul, Cha, Tae-Gweon, Jang, Pan-Ki, Kim, Chan-Woo, & Jang, Il Young. (2015). An Experimental Study on High Strength Concrete Using the LCD Waste Glass Powder. Journal of the Korean Recycled Construction Resources Institute, 3(4), 335–341. https://doi.org/10.14190/JRCR.2015.3.4.335 | |
| − | + | Toghroli, A., Shariati, M., Sajedi, F., Ibrahim, Z., Koting, S., Mohamad, E. T., & Khorami, M. (2018). A review on pavement porous concrete using recycled waste materials. Smart Structures and Systems, 22(4), 433–440. https://doi.org/10.12989/SSS.2018.22.4.433 | |
| − | + | Foti, D. (2013). Use of recycled waste PET bottles fibers for the reinforcement of concrete. Composite Structures, 96, 396–404. https://doi.org/10.1016/j.compstruct.2012.09.019 | |
| − | + | Babafemi, A. J., Šavija, B., Paul, S. C., & Anggraini, V. (2018). Engineering Properties of Concrete with Waste Recycled Plastic: A Review. Sustainability, 10(11), 3875. https://doi.org/10.3390/su10113875 | |
| − | + | Woo, G.-S., & Kim, J.-H. (2024). Experimental Research for the Manufacture of Recycled Aggregate Concrete of 30~40MPa or More That Satisfies Durability Design of Concrete Structures. Journal of the Korea Institute of Building Construction, 24(6), 619–630. https://doi.org/10.5345/JKIBC.2024.24.6.619 | |
| − | + | 엔.알.택 주식회사. 폐도자기와 폐애자를 경량 골재 대체재와 포장용 골재로 사용하는 재활용법 | |
| − | + | 이봉훈. 유리병컬럿을 경량 골재 대체재와 포장용 골재로 사용하는 재활용법 | |
| − | + | 김성환. 재활용 경량 복합 단열골재 | |
| − | + | Fahad Khshim Alqahtani. Recycled Plastic Aggregate for use in Concrete(US10294155B2) | |
| − | + | Francesco Piccone. Method for producing concrete using recycled plastic(WO2020000106A1) | |
| − | + | wooups. https://wooups.co.kr/33 | |
| − | + | 삼표그룹. https://sampyo.co.kr/ | |
| − | + | 지표누리. https://www.index.go.kr/ | |
| − | + | 순환자원정보센터. https://www.re.or.kr/info/listCirPricePage.do | |
| − | - | ||
| − | |||
| − | - | ||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
| − | |||
2025년 12월 2일 (화) 19:47 기준 최신판
프로젝트 개요
기술개발 과제
국문 : 재활용 소재, 폐기물을 사용한 경제적, 친환경 콘크리트 연구
영문 : Recycled and Eco-friendly Concrete Research
과제 팀명
1조
지도교수
김지수 교수님
개발기간
2025년 9월 ~ 2025년 12월 (총 4개월)
구성원 소개
서울시립대학교 토목공학과 2020860047 최효광(팀장)
서울시립대학교 토목공학과 2020860009 김민혁
서울시립대학교 토목공학과 2020860031 이정우
서울시립대학교 토목공학과 2020860033 조현진
서론
개발 과제의 개요
개발 과제 요약
본 과제에서는 꾸준히 증가하는 폐기물 처리를 위해 플라스틱 필렛, 물티슈를 대체제로 적용하여 제작 단가를 낮추고 탄소 배출을 줄이면서도 우수한 강도와 내구성을 확보하는 공법을 연구한다. 이를 통해 건설 산업의 자원 순환과 탄소중립 실현에 기여할 수 있는 지속 가능한 건설재료 기술을 제시하고자 한다.
◇ 목표 - 폐기물과 재활용 소재를 활용해 경제성 및 친환경성을 갖춘 콘크리트 개발
◇ 방법 - 플라스틱 필렛, 물티슈를 골재 대채제 및 첨가제로 활용
◇ 핵심성과 - 제작 단가 절감 - 탄소 배출 감소 - 강도 및 내구성 확보
개발 과제의 배경
◇ 폐기물 처리 문제 - 2026년부터 수도권 3개 시도 생활폐기물 직매립 전면금지 - 새로운 폐기물 자원화 기술 개발 필요성 증가
◇ 원자재 가격 상승 - 건설 자재 대부분을 수입에 의존하여 가격 불안정성 증가 - 최근 고환율이 지속되어 건설자재 비용 부담
◇ 탄소 중립 트렌드 - 글로벌 탄소 배출 감축 요구 강화와 ESG 경영의 확산 - 탄소 저감 기술 개발 필요성 및 친환경 건설 자재 개발 중요성 증가
개발 과제의 목표 및 내용
◇ 성능 목표 - 기존 콘크리트 대비 70% 이상 강도 확보
◇ 경제 목표 - 제작 원가 20% 절감 - 경제성 분석을 통해 사회적 비용 절감
◇ 환경목표 - 탄소 배출량 감소 - 폐기물 처리 및 재활용률 향상
관련 기술의 현황
관련 기술의 현황 및 분석(State of art)
- 전 세계적인 기술현황
전 세계적으로 탄소 중립 및 지속 가능한 건설기술 관련 연구 및 개발이 활발하다. 그중 본 과제와 관련 있는 폐기물·재활용 골재 활용 콘크리트 기술의 최신 동향과 연구 성과는 다음과 같다
Foti, D. (2012)
- PET 병을 절단하여 제작한 섬유로 보강한 콘크리트 공시체에 대해 연구를 진행. 콘크리트의 연성이 향상. 콘크리트와 PET 사이의 부착 성능이 우수하다는 결과
Kim, Byung-Chul et al. (2015)
- LCD 폐유리 미분말을 사용하여 고강도 콘크리트에 대한 연구를 진행. 대부분의 경우 강도가 저하되었으나 미분말의 입도 및 입경을 균질하게 한다면 강도가 향상될 것으로 평가
Toghroli, A. et al. (2018)
- 재활용 분쇄 유리, 강섬유, 폐타이어, 플라스틱 등의 폐기물을 이용한 포장용 포러스 콘크리트에 대해 연구시멘트 사용을 줄이고 폐기물 문제를 완화하는 효과 확인
Babafemi, A. et al. (2018)
- 폐플라스틱을 혼입하여 제작한 콘크리트의 기계적 특성과 내구성에 대해 연구. 압축강도, 휨강도 등의 특성들은 전반적으로 감소하였으나 공학적 요구를 충족, 폐플라스틱의 전처리 방법에 대해 추가 연구의 필요성을 제시
Yang, I.-H. (2021)
- 플라스틱 재활용 섬유를 콘크리트 제작에 사용하여 균열저항성 및 인장강도의 개선확인
Deng, J.-X. et al. (2023)
- 재활용 골재, 볏짚, 유약 처리한 구슬 등을 이용하여 재활용 단열 콘크리트를 개발. 기계적 성능 기준을 충족하면서 우수한 단열 성능을 제공하는 최적 배합비를 도출
Woo, G.-S., Kim, J.-H. (2024)
- 30~40MPa 이상의 순환골재 콘크리트 제조를 위한 실험적 연구를 진행. 해당 연구에서는 순환골재의 품질 개선 및 강도 증진을 위한 기초자료를 제공하여 순환골재 콘크리트의 폭넓은 활용을 도모
- 특허조사 및 특허 전략 분석
폐도자기와 폐애자를 경량 골재 대체재와 포장용 골재로 사용하는 재활용법
- 폐애자를 가능한 구에 가깝도록 파쇄, 연마하여 정형한 것을 천연 자갈을 대체할 수 있는 골재(상품명: 리포세라)로 사용. 아스팔트 포장의 노반 하층부의 쇄석의 일부로 사용. 골재에 열경화성 합성수지를 바인더로 사용하여 아스팔트 포장의 표층용 골재로 사용한다.
유리병컬럿을 경량 골재 대체재와 포장용 골재로 사용하는 재활용법
- 빈 병의 컬럿을 천연 모래의 경량골재 대체재나 컬러 투수 포장용 골재 등으로 사용하는 재활용법. 컬릿은 파쇄된 입체형의 입자로서 모서리각이 예리하여 위험성이 많으므로 새로 발명한 시스템을 적용
재활용 경량 복합 단열골재
- 스치로폴 발포체가 갖는 물성 중 단열성을 유지하면서 여러 강도를 증진시킬 수 있는 방법 관한 것. 강도, 색상, 모양, 크기 등도 다양하며 방습, 투습, 내부식성 또한 우수. 재활용 원료를 사용하므로 원료비 및 작업비용도 크게 절감
Recycled Plastic Aggregate for use in Concrete (US10294155B2)
- 폐플라스틱을 입자화해 콘크리트용 골재로 사용. 입자 크기 및 형상을 제어하여 시멘트와의 부착력을 개선
Method for producing concrete using recycled plastic (WO2020000106A1)
- 폐플라스틱을 골재로 활용한 단열 콘크리트 제조 공정. 플라스틱 골재에 시멘트 및 모래를 코팅하여 콘크리트 혼합물과의 부착력을 높이고 균일하게 혼합
시장상황에 대한 분석
부산항만공사(BPA)
- 케이슨 속채움재로 순환골재를 사용해 약 25억 원의 예산 절감 효과, 이산화탄소 배출 저감을 통한 약 121억 원 규모의 경제적, 환경적 편익을 창출
롯데건설
- 시멘트를 5%만 사용하고도 기존 대비 동등 이상의 강도를 발현하는 '저탄소 수화열 저감 콘크리트'개발, '고로 슬래그’가 80% 이상 포함, 첨가제가 일부 사용,고로 슬래그는 시멘트에 비해 탄소 배출량은 10분의 1, 가격은 시멘트의 70% 수준.
대우건설
- 자체 개발 저탄소 콘크리트를 아파트 전체 공사로 확대한다는 계획, 기존 대비 시멘트 사용량과 이산화탄소 배출량을 절반 넘게 줄이면서 강도 지연과 품질 하자 문제를 해소
포스코 이앤씨
- 저탄소 초고강도 콘크리트 파일 개발, 시멘트 대신 무수석고와 제철슬래그를 배합해 이산화탄소 발생량을 4% 수준으로 절감, 강도가 기존 파일보다 높아 시공 수량을 줄일 수 있어 공사 기간 단축과 원가 절감 가능
삼성물산 건설부문
- 콘크리트 생산 과정에 이산화탄소를 주입해 화학적 반응을 일으켜 콘크리트 강도를 높이는 기술을 확보, 시멘트 사용량과 비용 절감 가능, 이산화탄소가 콘크리트 내부에 저장되기 때문에 탄소 배출량이 70% 가까이 줄어드는 효과
개발과제의 기대효과
기술적 기대효과
- 재활용으로 건설 자재의 원료 다양성 확대 - 재료에 따른 콘크리트의 강도, 내구성 등 특성 변화 파악 가능 - 폐기물 전처리 방식에 따라 접착력, 공극률 등이 달라지므로 최적 조건 도출 가능 - 경량화, 단열성 등 특정 성능을 개선 가능 - 요구 특성에 따른 맞춤형 콘크리트 제작 가능
경제적, 사회적 기대 및 파급효과
- 건설 재료의 가격이 상승하는 상황에서 원가 절감 가능 - 시공 수량을 줄여 공사 기간 단축 가능 - 산업 및 생활폐기물의 처리 비용 절감, 지자체 및 기업의 부담 완화 - 폐기물 처리 문제를 일부 해결, 생산 과정의 탄소 배출량 감소 가능 - 환경 보호 및 친환경 건설 기술 실현에 기여
기술개발 일정 및 추진체계
개발 일정

구성원 및 추진체계
건설순환 재료학회, 콘크리트 학회지 자료를 참조한 다양한 배합의 공시체를 시험하여 최적의 배합을 찾는 과정을 반복합니다.
설계
설계사양
제품의 요구사항

설계 사양

개념설계안

배합비 물:시멘트:잔골재=1:2:4.8
필렛량 잔골재 무게의 15%
물티슈량 공시체 부피의 0%, 1%, 2%, 4%
상세설계 내용
배합비
기본 공시체


플라스틱 필렛 포함 공시체


물티슈량


일축압축강도 시험
기본공시체 6개와 필렛을 넣고 물티슈를 다르게 넣은 공시체 각각 6개씩 총 30개의 공시체를 제작한다.
각각의 공시체 중 5개를 선정해 일축압축강도 시험을 실시하고 그 값을 정리한다.


휨강도 실험
일축압축강도와 같은 배합으로 각각 3개씩 총 15개의 공시체를 제작한다.


결과 및 평가
실험결과
일축압축강도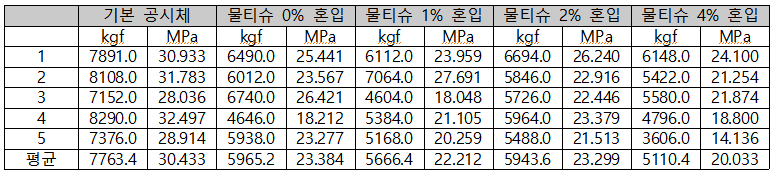
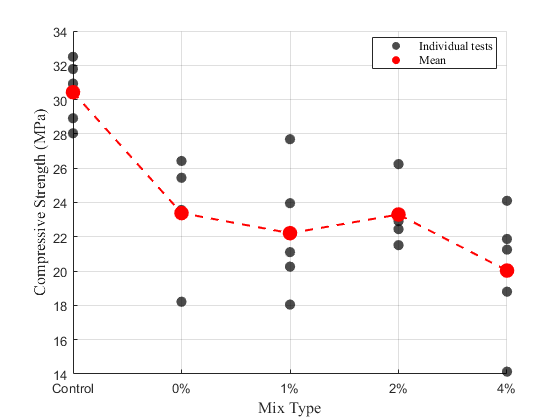


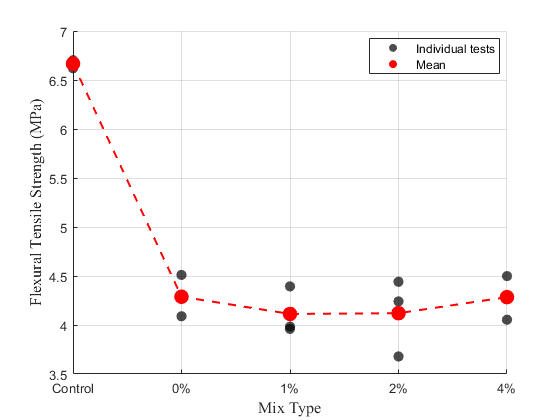
휨강도 실험


평가
환경성 평가
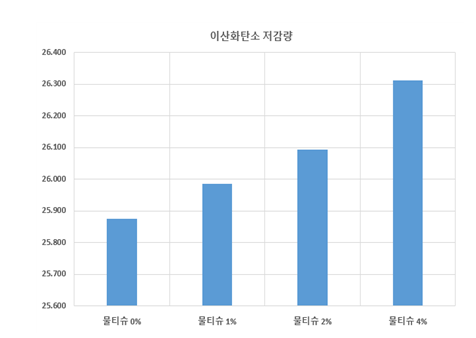


-공시체 6개 제작 과정에서 사용된 폐플라스틱–섬유의 질량을 기준으로 환경적 편익을 산정하였다. 분석 결과, 공시체 6개를 제작하는 과정에서 약 26g CO₂의 온실가스 배출 저감 효과가 확인되었다. 이는 동일한 양의 폐플라스틱을 매립 처리했을 때 발생하는 온실가스 배출을 재활용을 통해 직접적으로 차단한 효과에 해당한다. -특히 폐기물의 매립은 분해 과정에서 장기적인 온실가스 배출을 야기하는데, 본 연구의 재활용 방식은 이러한 배출원을 근본적으로 감소시키는 결과를 초래한다. 비록 개별 실험 단위에서는 수 g 단위의 저감 효과로 나타났지만, 이는 대량 생산 시 누적 효과가 기하급수적으로 커진다는 점에서 환경적 가치가 크다. -예컨대 동일한 배합을 산업 규모로 확대할 경우, 수백 kg에서 수 톤 단위까지 CO₂ 절감이 가능해져 건설 산업의 온실가스 감축에 실질적으로 기여할 잠재력을 지닌다. 종합적으로, 폐플라스틱 활용 콘크리트는 폐기물 매립을 감소시키는 동시에 온실가스 배출을 줄임으로써 높은 환경성 개선 효과를 보였으며, 이는 본 연구의 환경성 개발 목표(폐기물 감량 및 CO₂ 배출 저감)를 충분히 충족하는 것으로 평가된다.
경제성 평가
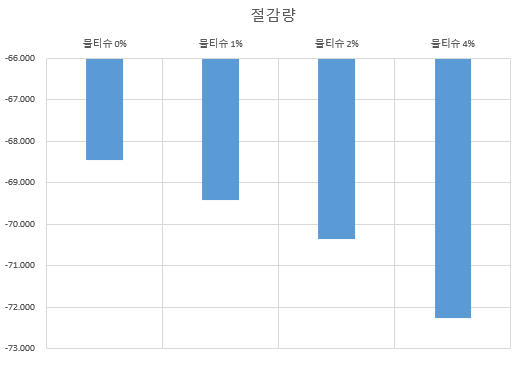


-공시체 6개 제작 과정에서 사용된 폐플라스틱–섬유의 질량을 기준으로 경제적 편익을 산정하였다. 분석결과 우선 재료비 측면에서, 폐플라스틱을 골재로 치환함으로써 약 3.09원의 골재 비용 절감이 발생하였으며, 동일한 양의 폐기물을 매립하지 않음에 따라 약 90원의 폐기물 처리비 절감 효과가 추가로 발생하였다. -다만 폐기물을 재료로 활용하기 위해 반드시 필요한 전처리 과정에서 약 164원의 추가 비용이 발생하는 것으로 확인되었다. 약 70원 정도의 가격이 증가되어, 오히려 사용하지 않을 때 경제적 이점이 있는 것으로 나타났다. -폐플라스틱의 전처리 과정과 기업들의 친환경 사업 확대, 유가 상승에 의한 플라스틱 가격 상승이 폐플라스틱 필렛의 가격 상승의 요인으로 판단된다.
강도 평가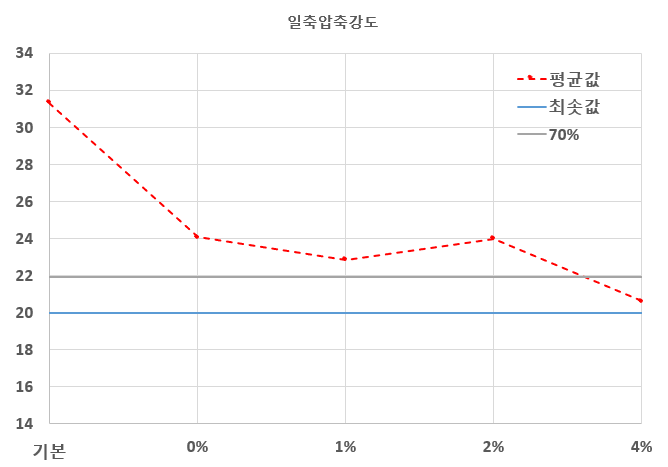
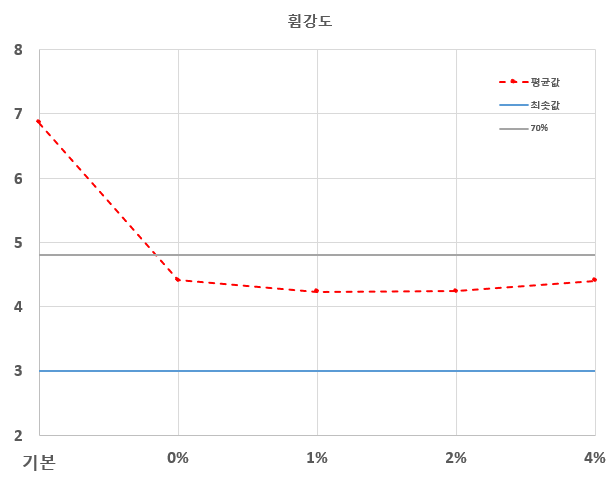


-혼입률이 증가함에 따라 압축강도는 전반적으로 감소하는 경향을 보였으며, 그중 4% 혼입 배합의 28일 추정 압축강도는 20.6 MPa로 나타났다. 이는 기준 콘크리트 대비 약 65.8% 수준으로, 본 연구의 주목적이었던 기준 콘크리트 강도 대비 70% 확보에는 미치지 못하였다. 또한 휨강도는 대부분이 기존 콘크리트 강도 대비 70% 이하의 수치를 나타냈다. 즉, 구조용 콘크리트 수준의 성능을 확보하는 데에는 한계가 있는 것으로 평가되었다. -그러나 재활용 콘크리트의 활용은 반드시 구조용 용도에만 한정되는 것은 아니다. 이에 따라 본 연구에서는 두 번째 목표로 비구조용 포장재(보도블록·조경 블록 등)로의 활용 가능성을 평가하였다. 이를 위해 일반적으로 산업 현장에서 사용되는 기능적 최소 기준인 압축강도 20 MPa 이상, 휨강도 3 MPa 이상을 적용하였다. -4% 혼입 배합의 압축강도는 20.6 MPa로 이 기준을 충족하였으며, 휨강도 역시 평균 4.41 MPa로 나타나 비구조용 포장재 적용 기준인 3 MPa을 충분히 상회하였다. 또한 KS F 4419 보도블록 규격의 최저 휨강도 기준(3.5 MPa) 역시 충족하는 것으로 확인되었다. 다만 KS 규격의 평균강도 기준(5.0 MPa)에는 조금 부족한 수치를 보였다.
완료 작품의 소개
포스터
완료작품의 평가
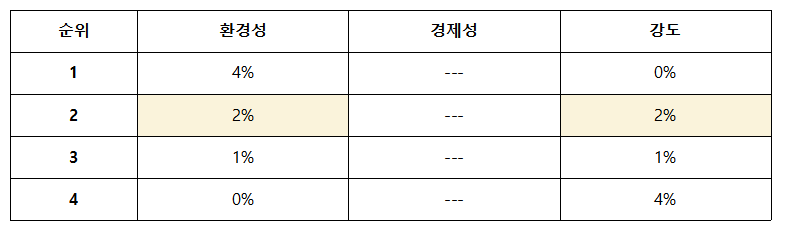

-평가 결과 환경성 면에서는 물티슈 4% 혼입된 배합이 유리하나 강도 면에서 실제 현장에서 사용되기에 무리가 있다. 따라서, 경제성을 제외한 평가에서 준수한 결과를 얻은 물티슈 2% 혼입된 배합을 최적 배합비로 선정했다.
-본 과제에서 개발된 재활용 폐기물 콘크리트는 강도, 환경성, 경제성을 종합적으로 분석한 결과, 추가적인 연구를 통한 상용화 가능성이 확인되었다. 건설 산업에서의 자원 순환형 콘크리트로 발전할 잠재력이 높다고 판단하였다. -본 과제의 재활용 콘크리트는 강도 측면에서 기존 구조용 콘크리트의 표준 압축강도 기준과 비교했을 때 일부 조건에서는 적용에 제한이 있을 수 있다. 하지만 비구조용 콘크리트, 보도 블럭, 도로용 콘크리트 등 저하중 환경에서 충분한 활용이 가능한 성능을 확보하였다. 실제 국내 도로 포장용 콘크리트 및 보도재 기준과 비교했을 때, 본 연구에서 제조된 시편은 기준 강도를 충족하거나 근접한 수준을 나타냈으며, 이는 초기 상용화를 위한 적용 분야가 명확히 존재함을 의미한다. -제조 과정에서 사용된 폐기물 재료의 형상적 특성 중 플라스틱 필렛의 큰 크기, 매끄러운 표면 등은 콘크리트 내부에서 결합력 감소 및 미세 균열의 원인으로 작용한 것으로 판단된다. 따라서 향후 연구에서 재활용 재료의 표면 거칠기 증가 처리, 필렛 크기 최적화 등을 연구할 경우, 강도가 현재 수준보다 향상될 것으로 예상된다. 이를 통해 장기적으로는 구조용 콘크리트의 강도 수준을 확보할 수 있을 것으로 기대된다. -환경성 측면에서도 본 재활용 콘크리트는 의미있는 결과를 보였다. 폐기물 기반 재료 활용은 매립량 및 탄소 배출량 감소, 자원 재활용률 증대라는 효과를 가져온다. 이는 국내·외 건설 산업에서 요구되고있는 ESG 정책 및 탄소중립 목표와 방향성이 일치한다. 특히, 정부·지자체의 순환자원 의무 사용 정책, 녹색건축 인증제도와 연계될 경우 시장 확장성이 매우 크다. -경제성 측면에서는 재활용 폐기물로 대체하면 비용이 증가되는 결과가 나타났다. 하지만 폐기물 전처리 공정이 대규모로 구축된다면 폐기물 전처리에 드는 비용이 감소하여 비용이 감소할 것으로 예상된다. -따라서 본 연구과제는 기술적 완성도 향상과 규격화 작업을 지속한다면, 향후 지속 가능한 건설 산업과 친환경 콘크리트 시장 확대에 중요한 역할을 수행할 수 있을 것으로 예상된다.
참고 문헌
Yang, I.-H. (2021). Manufacturing and characteristics of recycled plastic fiberreinforced concrete. Magazine of RCR, 16(1), 17–22. https://doi.org/10.14190/MRCR.2021.16.1.017 Kim, Byung-Chul, Cha, Tae-Gweon, Jang, Pan-Ki, Kim, Chan-Woo, & Jang, Il Young. (2015). An Experimental Study on High Strength Concrete Using the LCD Waste Glass Powder. Journal of the Korean Recycled Construction Resources Institute, 3(4), 335–341. https://doi.org/10.14190/JRCR.2015.3.4.335 Toghroli, A., Shariati, M., Sajedi, F., Ibrahim, Z., Koting, S., Mohamad, E. T., & Khorami, M. (2018). A review on pavement porous concrete using recycled waste materials. Smart Structures and Systems, 22(4), 433–440. https://doi.org/10.12989/SSS.2018.22.4.433 Foti, D. (2013). Use of recycled waste PET bottles fibers for the reinforcement of concrete. Composite Structures, 96, 396–404. https://doi.org/10.1016/j.compstruct.2012.09.019 Babafemi, A. J., Šavija, B., Paul, S. C., & Anggraini, V. (2018). Engineering Properties of Concrete with Waste Recycled Plastic: A Review. Sustainability, 10(11), 3875. https://doi.org/10.3390/su10113875 Woo, G.-S., & Kim, J.-H. (2024). Experimental Research for the Manufacture of Recycled Aggregate Concrete of 30~40MPa or More That Satisfies Durability Design of Concrete Structures. Journal of the Korea Institute of Building Construction, 24(6), 619–630. https://doi.org/10.5345/JKIBC.2024.24.6.619 엔.알.택 주식회사. 폐도자기와 폐애자를 경량 골재 대체재와 포장용 골재로 사용하는 재활용법 이봉훈. 유리병컬럿을 경량 골재 대체재와 포장용 골재로 사용하는 재활용법 김성환. 재활용 경량 복합 단열골재 Fahad Khshim Alqahtani. Recycled Plastic Aggregate for use in Concrete(US10294155B2) Francesco Piccone. Method for producing concrete using recycled plastic(WO2020000106A1) wooups. https://wooups.co.kr/33 삼표그룹. https://sampyo.co.kr/ 지표누리. https://www.index.go.kr/ 순환자원정보센터. https://www.re.or.kr/info/listCirPricePage.do