Vision
목차
- 1 프로젝트 개요
- 1.1 기술개발 과제
- 1.2 과제 팀명
- 1.3 지도교수
- 1.4 개발기간
- 1.5 구성원 소개
- 1.6 서론
- 1.7 설계
- 1.7.1 설계사양
- 1.7.2 개념설계안
- 1.7.3 이론적 계산 및 시뮬레이션
- 1.7.3.1 AI 추천 모델
- 1.7.3.2 1. AUTO_ENCODER
- 1.7.3.3 2. EASE (Embarrassingly Shallow Autoencoders for Sparse Data)
- 1.7.3.4 데이터셋
- 1.7.3.5 평가지표
- 1.7.3.6 모델별 정확도 비교
- 1.7.3.7 태그 그룹 선정
- 1.7.3.8 JWT 사용자 인증
- 1.7.3.9 백준 문제 크롤링 로직
- 1.7.3.10 Quiz 생성 로직
- 1.7.3.11 ERD
- 1.7.3.12 흐름도
- 1.7.3.13 ELO 시스템
- 1.7.3.14 유저 취약 TAG 기반 Problem 추천
- 1.7.4 상세설계 내용
- 1.8 결과 및 평가
프로젝트 개요
기술개발 과제
국문 : 코테고리 서비스 - 알고리즘 유형분류 퀴즈 및 문제 추천 서비스
영문 : Cotegory Service - Algorithm type classification quiz and problem recommendation service
과제 팀명
Vision
지도교수
황*수 교수님
개발기간
2023년 3월 ~ 2023년 6월 (총 4개월)
구성원 소개
서울시립대학교 컴퓨터과학부 20189200** 류*욱(팀장)
서울시립대학교 컴퓨터과학부 20179200** 김*
서울시립대학교 컴퓨터과학부 20184300** 김*철
서울시립대학교 컴퓨터과학부 20189200** 임*욱
서울시립대학교 컴퓨터과학부 20189200** 한*한
서론
개발 과제의 개요
개발 과제 요약
◇ 사용자 수준에 맞춘 알고리즘 문제 유형 분류 퀴즈 제공
◇ 오답률이 높은 문제 유형의 알고리즘 분야 파악 및 문제 추천 기능 제공
◇ 퀴즈 결과를 기반으로 한 프로필 요약 제공
◇ 취업 및 자기계발이 서비스의 주 목적으로 취준생이 주요 타겟층
개발 과제의 배경
◇ IT 분야의 기업에 취업을 희망하는 경우, 다수의 기업이 알고리즘 코딩테스트를 기업의 전형에 포함하고있어, 알고리즘 학습에 대한 수요가 많은 상황이다.
◇ 알고리즘 문제를 읽고 접근방식에 대한 충분한 검토 없이 바로 풀이에 들어가는 사용자가 있다.
개발 과제의 목표 및 내용
◇ 알고리즘 대회 또는 코딩테스트를 준비하는 사용자가 쉽게 자신의 알고리즘 역량을 확인하고, 향상시킬 수 있는 웹 플랫폼을 개발한다.
◇ 퀴즈 결과를 통해 요약 프로필을 제공하고 이를 통해 자신의 알고리즘 풀이 능력을 한 눈에 확인할 수 있게 한다.
◇ 퀴즈 결과를 통해 취약한 알고리즘 유형의 문제를 추천하여 자연스럽게 구현까지 이어지게 한다.
◇ 사용자가 서비스를 활용할 수록 알고리즘 풀이에 흥미를 갖게하여 꾸준하게 Cotegory 서비스를 이용할 수 있도록 한다.
관련 기술의 현황
관련 기술의 현황 및 분석(State of art)
- 전 세계적인 기술현황
- - 알고리즘 문제풀이는 알고리즘 유형파악과 코드구현 부분으로 나누어 볼 수 있다.
- - 현존하는 온라인 알고리즘 문제풀이 사이트는 대부분 코드구현 부분에 포커스가 맞춰져 있다.
- - 본 Vision은 알고리즘 유형파악에 포커스를 맞춘 서비스를 개발한다.
- 특허조사 및 특허 전략 분석
- - (주)뤼이드. 인공 지능 학습 기반의 학습 컨텐츠 추천 시스템 및 그것의 동작 방법. 10-2021-0014455. 2021년 2월 2일, 2022년 4월 29일
- - (주)뤼이드. 온라인 학습에서 적응형 사용자 인터페이스를 제공하는 방법 및 장치. 10-2020-0024119. 2020년 2월 27일, 2021년 2월 2일
- - (주)뤼이드. 교육 컨텐츠를 제공하는 방법, 장치 및 컴퓨터 프로그램. 10-2019-0024272. 2019년 2월 28일, 2021년 2월 2일
- 기술 로드맵

시장상황에 대한 분석
- 경쟁제품 조사 비교
- ◇ Baekjoon
- 대표적인 알고리즘 문제 해결 서비스
- 알고리즘 문제를 코드를 작성하여 직접 해결 할 수 있으나 알고리즘 문제에 대한 카테고리를 맞추는 문제는 제공하지 않음.
- 사용자에게 문제를 추천해주는 서비스는 제공해주지 않음.
- 대표적인 알고리즘 문제 해결 서비스
- ◇ Programmers (스킬체크)
- 사용자가 스스로 생각하는 레벨별로 알고리즘 문제를 제공 후 평가해주는 서비스
- 사용자의 코드의 정확성과 효율성을 판단할 수 있음
- 사용자가 스스로 생각하는 레벨별로 알고리즘 문제를 제공 후 평가해주는 서비스
- ◇ Solved.ac (프로필 제공 측면)
- Baekjoon 사이트의 기록을 기반으로 문제와 사용자의 프로필을 제공해주는 서비스
- 사용자의 수준과 문제의 난이도를 파악할 수 있음.
- 직접적인 문제를 풀 수 있는 서비스르 제공해주지는 않음.
- Baekjoon 사이트의 기록을 기반으로 문제와 사용자의 프로필을 제공해주는 서비스
- ◇ 산타 토익
- 사용자가 푼 문제 결과를 기반으로 토익 문제를 추천해주는 영어 공부 서비스
- 첫 12문제의 결과 값을 이용하여 사용자에게 적합한 문제를 추천해준다.
- 토익 시험 응시생을 대상으로 한다.
- 사용자가 푼 문제 결과를 기반으로 토익 문제를 추천해주는 영어 공부 서비스
| 서비스 타겟 | 추천 서비스 | 문제 제공 서비스 | 프로필 제공 | |
|---|---|---|---|---|
| 백준 | 알고리즘을 해결하고자 하는 사용자 | 존재하지 않음. | 알고리즘 문제 제공 | 간단한 정보 제공 |
| solved.ac | 백준을 사용하는 사용자 | 존재하지 않음. | 제공하지 않음 | 사용자 맞춤형 정보 제공 |
| programmers | 알고리즘을 해결하고자 하는 사용자 | 존재하지 않음. | 알고리즘 문제 제공 | 간단한 정보 제공 |
| 산타 토익 | 토익을 준비하는 사용자 | 사용자의 수준에 맞는 문제 추천 | 토익 문제 제공 | 사용자 맞춤형 정보 제공 |
| 코테고리 | 취업을 준비하는 사용자 | 사용자의 수준에 맞는 문제 추천 | 알고리즘 카테고리 문제 제공 | 사용자 맞춤형 정보 제공 |
- 마케팅 전략 제시
- ◇ 코딩테스트 준비를 시작하려는 취업 준비생들에게 본인의 알고리즘 역량을 쉽게 파악할 수 있는 점을 강조한다.
- ◇ 기존 서비스에는 존재 하지 않던 "카테고리"를 맞추는 문제를 제공해 준다는 점을 강조한다.
- ◇ 사용자가 어려워하는 유형의 문제를 추천하여 문제 해결에 대한 취약점 개선 가능성을 강조한다.
- ◇ 사용자에게 설문조사를 실시한다.
개발과제의 기대효과
기술적 기대효과
◇ 알고리즘 유형 분석 능력 증진
◇ 취약한 분야의 알고리즘 문제를 추천받을 수 있다
◇ 기업 코딩테스트 대비
경제적, 사회적 기대 및 파급효과
◇ 알고리즘 접근 난이도 하향
◇ 알고리즘 풀이에 대한 흥미 유발
◇ 교육 자료로 활용
기술개발 일정 및 추진체계
개발 일정
| 기술 로드맵 구성 | 진행 순서 (월단위) | |||
|---|---|---|---|---|
| 3 | 4 | 5 | 6 | |
| 프로젝트 구상 및 구체화 | ||||
| DB 설계 | ||||
| UI 설계 | ||||
| 추천 모델 데이터 수집 및 학습 | ||||
| AI 서버 제작 | ||||
| API 서버 제작 | ||||
| 웹 제작 | ||||
| 설문 조사 | ||||
| 릴리즈 버전 테스트 | ||||
구성원 및 추진체계
◇ Front-end (류병욱)
UI/UX 프론트 페이지 HTML 작성 Back-end와의 통신코드 작성
◇ Back-end (김준)
mmr시스템 로직 구현 mmr시스템을 통한 Quiz 추천 기업문제 추천 기능 구현
◇ Back-end (김형철)
크롤링 로직 구현 JWT 로그인 구현 어드민 페이지 API 개발 비정상적 문제 검열 로직
◇ Back-end (김준 & 김형철)
서비스 로직 API 개발
◇ AI (한수한)
모델 학습 모델 평가 & 비교(EASE, AUTO_ENCODER)
◇ 아마존 배포 (임재욱)
인프라 세팅 웹서버 배포(서버, DB) CI/CD 적용
설계
설계사양
제품의 요구사항
◇ R1: 알고리즘 퀴즈를 풀고 이력을 확인할 수 있다.
◇ R2: 취약한 알고리즘 분야에 대한 추천을 받을 수 있다.
◇ R3: 다양한 알고리즘 문제를 추천받을 수 있다.
◇ R4: 요약 프로필을 제공받을 수 있다.
설계 사양
◇ F1:
- 기능: 알고리즘 퀴즈를 하나씩 제공하고 정답 여부가 기록되어 마이페이지에서 제공한다.
- 정량 목표:
- - AI: AUTO_ENCODER 모델을 적용하여 추천 문제를 선별하여 Back-end 서버에 제공한다.
- - Back-end: 알고리즘 퀴즈를 Front-end 서버에 전달하며, 정답 여부를 db에 저장한다.
- - Front-end: Back-end 서버로부터 전달받은 추천 문제와 알고리즘 퀴즈 문제를 화면에 보이고 문제를 풀 수 있는 UI를 제공한다.
◇ F2:
- 기능: 유저로부터 전달받은 정보를 활용하여 AI 모델을 통해 적합한 문제를 추천한다.
- 정량 목표:
- - AI: 유저가 취약한 알고리즘 분야의 문제를 추천받고자 하는 경우, AUTO_ENCODER 모델을 적용하여 추천 문제를 선별하여 Back-end 서버에 제공한다.
- - Back-end: 추천 문제를 Front-end 서버에 전달한다.
- - Front-end: Back-end 서버로부터 전달 받은 추천 문제를 화면에 보이고 문제를 풀 수 있는 링크 또한 제공한다.
◇ F3: 랜덤 문제, 유저가 취약한 알고리즘 분야의 문제, 기업 문제를 추천한다.
- 기능: 유저로부터 전달받은 정보를 활용하여 AI 모델을 통해 적합한 문제를 추천한다.
- 정량 목표:
- - AI: AUTO_ENCODER 모델을 적용하여 추천 문제를 선별하여 Back-end 서버에 제공한다.
- - Back-end: 추천 문제를 Front-end 서버에 전달하며, 오늘의 추천 문제와 기업 문제 또한 Front-end 서버에 전달한다.
- - Front-end: Back-end 서버로부터 전달받은 추천 문제를 화면에 보이고 문제를 풀수 있는 링크 또한 제공한다.
◇ F4: 문제 히스토리와 요약 프로필을 제공한다.
- 기능: 퀴즈 결과와 알고리즘 대분류별 MMR을 제공한다.
- 정량 목표:
- - Back-end: 퀴즈 결과와 알고리즘 대분류별 MMR 점수를 Front-end에 전달한다.
- - Front-end: Back-end 서버로부터 전달받은 데이터를 화면에 보이고 데이터를 가공하여 100점 만점을 기준으로 점수를 보여주며 능력치를 progress bar 형태로 보여준다.
개념설계안


1. EC2 Instance와 Docker Container: EC2 인스턴스에서 Docker를 실행하고, Docker 컨테이너를 생성하여 애플리케이션을 실행합니다.
2. Dockerfile과 Docker Image: Dockerfile은 Docker 이미지를 작성하는데 사용됩니다. Docker 이미지는 애플리케이션과 애플리케이션 실행에 필요한 모든 종속성을 포함하는 실행 가능한 패키지입니다.
- Dockerfile은 총 3개로, 각각 AI, Front-end, Back-end 도메인을 의미합니다.
- Dockerfile은 총 3개로, 각각 AI, Front-end, Back-end 도메인을 의미합니다.
3. Docker Compose.yml과 Docker Compose: Docker Compose는 여러 개의 Docker 컨테이너를 정의하고 관리하는 데 사용되는 도구입니다. Docker Compose.yml 파일은 Docker Compose가 사용하는 설정 파일입니다.
4. AWS S3와 EC2 Instance: EC2 인스턴스는 AWS S3에 접근하여 데이터를 읽거나 쓸 수 있습니다. 이를 통해 EC2 인스턴스와 S3 버킷 간에 파일 공유 또는 데이터 저장 등의 작업이 가능합니다.
5. AWS RDS와 EC2 Instance: EC2 인스턴스는 AWS RDS(Relational Database Service)에 접근하여 데이터베이스에 연결하고 데이터를 읽거나 쓸 수 있습니다. 이를 통해 애플리케이션과 데이터베이스 간의 상호작용이 가능합니다.
6. 프로젝트 코드의 갱신을 고려하여 GitHub Actions를 사용하여 CI/CD를 적용하였습니다.
이론적 계산 및 시뮬레이션
AI 추천 모델
◇ 기본적으로 훈련에 쓰인 데이터외의 데이터를 통해서도 문제를 추천해줄 수 있는 모델을 선정하였다.
◇ auto_encoder 모델이 위의 특성을 가지고 있어 auto_encode 기본 모델(AUTO_ENCODER)과 간단하면서도 성능이 좋은 모델(EASE)을 선정하였다.
1. AUTO_ENCODER

《특징》
입력 데이터(X)를 encoder에 넣어 잠재 벡터로 만든후 이 잠재 벡터를 다시 decoder에 넣어 입력 데이터와 비슷한 출력 데이터로 복원하는 형태를 가진다.
입력 데이터를 원래의 입력데이터의 압축된 지식표현으로 만드는 것이 목적이지만 이는 추천에도 활용할 수 있다.
훈련을 너무 오래 돌리면 auto encoder의 weight의 곱이 단위 행렬과 비슷해질 수 있다.
즉, 대각 값이 가장 높아져 자기 자신이 자기 자신을 추천해버리는 경우가 생긴다. (overfitting)
그러므로 훈련을 적당한 선에서 멈추고 대각 값에 제약을 추가하는 방법을 사용한다.
본 프로젝트에서는 hidden layer를 2개(Encoder, Decoder)만 사용했다.
《학습 방법》
◇ 데이터 (X)
- X = 유저(U) * 아이템(I) Matrix
- 0과 1로 이루어짐
◇ 파라미터
- E = 아이템(I) * 잠재벡터차원(Z) Matrix
- - 입력 데이터를 잠재 벡터로 encoding하는 작업을 수행
- D = 잠재벡터차원(Z) * 아이템(I) Matrix
- - 잠재 벡터를 입력 데이터처럼 decoding하는 작업을 수행
◇ 출력 (S)
- S = X * E * D
- 유저(u)에 대한 아이템(j)의 ranking 점수
《목적함수 (손실함수)》
본 프로젝트에서는 손실함수 L을 auto_encoder에 흔히 쓰이는 mse(mean squared error)로 설정했다.


훈련 루프를 돌며 L을 최소화하도록 훈련한다.
단, 위에서 언급한 것처럼 L을 최소화하다보면 train data의 정확도는 높아지고 test data의 정확도는 낮아지는overfitting이 발생하므로 est data의 정확도가 최대일 때의 모델(가중치)를 저장한다.
2. EASE (Embarrassingly Shallow Autoencoders for Sparse Data)
《특징》
2019년에 나온 추천 모델로 hidden layer가 없는 shallow한 모델이다.
다른 딥러닝 모델과 달리 학습 파라미터(매트릭스)가 1개밖에 존재하지 않고 이 학습 파라미터의 대각 성분을 0으로 함으로써 목적함수를 closed form sulution로 만들 수 있어 최적의 해를 구할 수 있다.
《학습 방법》
◇ 데이터 (X)
- X = 유저(U) * 아이템(I) Matrix
- 예시
문제 1 문제 2 문제 3 문제 4 유저 A 0 1 1 0 유저 B 1 0 1 1 유저 C 0 0 0 1

◇ 파라미터 (B)
- I * I Matrix
- 예시

◇ 출력 (S)
- S = X * B
- 예시

《목적함수 (손실함수)》

◇ X와 XB 의 차이를 가장 작게 하는 B를 구하는 항에 과적합을 예방하기 위한 L2-norm정규화 항을 추가한다.
◇ 위에서 볼 수 있듯이 EASE 모델에서는 하이퍼파라미터(hyperparamter)는 밖에 없다.
◇ B의 값을 구하기 위해 대각 성분을 0으로 한다는 조건을 사용하여 라그랑주 승수법을 이용한다.
◇ 라그랑주 승수법을 통해 생성된 최종 목적함수는 다음과 같다.

◇ L이 최소가 되는 B를 구하는 중간 과정이 논문에 존재하지 않아 간단히 증명하면 다음과 같다.
- 위 식에서 L2-norm 제곱 항을 다음과 같이 변경할 수 있다.
- 위 식을 사용한 최종 손실함수 L은 다음과 같다.
- L을 미분하여 L의 도함수가 0이 되는 B를 구하는 과정은 다음과 같다.
- 각 항에 대해 미분을 진행하면 다음과 같은 식이 나온다.
- L의 도함수를 0으로 하여 B에 대해 정리하면 논문에서 나온 B의 항등식이 나온다.
- 다음부터는 논문에 있는 내용이다.먼저 식을 간추리기 위해 다음과 같이 P를 정의한다.
- B에 P를 대입하여 정리하면 다음과 같다.
- 마지막으로 γ̃을 구하고
- γ̃을 B식에 대입하면
- 즉, 이 과정으로 구한 B가 L이 최소가 되는 최적의 해가 된다.B의 요소를 표현해보면
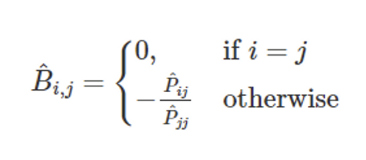
- 즉, 대각 값은 전부 0이고 그렇지 않으면 P에 영향을 받는다.
- P은 위 식에서 볼 수 있듯이 X^TX에 영향을 받는다.
- 이때, X^TX는 $라고 표현하는데 이는 Gram Matrix라고 한다.
- G는 item-item matrix로 co-occurrence matrix(동시 발생 행렬)라고도 불리운다.
- G를 본 프로젝트에 적용하자면 어떤 문제를 선택했을 때, 다른 문제도 선택될 빈도를 나타낼 수 있는 지표이다.
- 즉, 문제와 문제의 유사성을 띄는 matrix로 추천에 용이하게 쓰인다.








데이터셋
◇ 데이터는 백준 유저 랭킹 31~280 페이지에서 10명씩 총 2500명을 sampling하여 얻었다.
◇ 데이터를 얻은 2023/05/03 기준 280페이지는 한 유저가 최소 162문제를 풀었다.
◇ train data와 test data를 7:3으로 나누고 topk를 50까지 하기 위해서 위와 같이 sampling하였다.
- 162*0.3 ~= 49이므로 대부분의 유저가 test data에 들어갈 수 있다.
◇ train data와 test data를 나누는 방법은 다음과 같다.
ex) 유저 3명, 문제 5개
[[1,0,1,1,1], [0,0,1,1,1], [1,1,1,0,0]] shape = (3,5)
[(0,4), (1,2), (2,0)]
[[1,0,1,1,0], [0,0,0,1,1], [0,1,1,0,0]]
train data를 모델에 넣어 train data에서 이미 1인 data를 제외하고 rating을 매긴 후 유저별로 가장 높은 1개의 문제를 고른다. 이때, 이 문제가 test data에 속한다면 true로 판정한다. ex)
[[0.8, 0.1, 0.9, 0.3, 0.15], [0.1,0.05 , 0.09, 0.6, 0.4], [0.2, 0.3, 0.7, 0.1, 0.12]]
[[0.8, 0.1, 0.9, 0.3, 0.15], [0.1,0.05 , 0.09, 0.6, 0.4], [0.2, 0.3, 0.7, 0.1, 0.12]] (0,4), (1,0), (2,0) // rating 결과 index |
평가지표
◇ precision
◇ recall
◇ ndcg
총 3가지로 평가한다.
ex) 문제 총 개수 = 10 어느 유저가 푼 문제 matrix test_ratio = 0.3 topk = 3 유저에 대한 rating = [0.9, 0.1, 0.2, 0.4, 0.6, 0.3, 0.2, 0.1, 0.8, 0.1] train_maxtix 에서 1인 index는 rating에서 -INF으로 변경 (훈련에 쓰인 문제는 추천 X) 이제 rating에서 상위 3개 index를 뽑으면 [0.6, 0.4, 0.3]의 index인 [4, 3, 5]가 된다. test_data에 속한 rating의 개수는 3,4 총 2개이므로 precision = 2/3 = 0.67, |
모델별 정확도 비교
| Model | Precision@10 | Recall@10 | nDCG@10 |
|---|---|---|---|
| EASE | 0.9614 | 0.1255 | 0.9691 |
| AUTO_ENCODER | 0.9595 | 0.1252 | 0.9670 |
| AUTO_ENCODER_CONST | 0.9647 | 0.1259 | 0.9712 |
| Model | Precision@20 | Recall@20 | nDCG@20 |
|---|---|---|---|
| EASE | 0.9259 | 0.2404 | 0.9418 |
| AUTO_ENCODER | 0.9259 | 0.2403 | 0.9410 |
| AUTO_ENCODER_CONST | 0.9292 | 0.2413 | 0.9443 |
◇ EASE 모델은 대각선을 제한하지 않은 AUTO_ENCODER 모델보다 성능은 좋지만 대각 성분을 제한한 모델인 AUTO_ENCODER_CONST보다는 정확도가 낮다.
◇ 모든 부분을 보았을 때 AUTO_ENCODER_CONST가 가장 성능이 좋아 본 프로젝트에서는 대각 성분을 제한한 AUTO_ENCODER_CONST 모델을 추천에 사용하기로 결정하였다.
◇ 참고로 랜덤추천의 정확도는 아래와 같다.
| Model | Precision@10 | Recall@10 | nDCG@10 |
|---|---|---|---|
| RANDOM | 0.0025 | 0.0003 | 0.0027 |
위 결과에서 볼 수 있듯이 랜덤 추천의 정확도는 본 추천 모델보다 성능이 비약하다. 이는 전체 문제 수에 비해 유저가 푼 문제 수가 매우 적어서 나타나는 현상이고 유저가 문제를 푸는 성향이 서로 비슷하기 때문이다. 즉, 실제 유저가 문제를 푸는 성향이 비슷하다는 것은 서로 그 문제들을 풀 가능성이 높다는 것이기에 추천 정확도가 높은 본 추천 모델을 사용하는 것은 추천의 타당성이 있다고 볼 수 있다.
태그 그룹 선정
본 프로젝트에서 태그 유형 분류 퀴즈에 쓰일 태그로 다음과 같은 총 10개의 태그를 선정하였다.
- 그리디 알고리즘(탐욕 알고리즘)
- 다이나믹 프로그래밍
- 브루트포스 알고리즘(완전 탐색)
- 이분 탐색
- 너비 우선 탐색(bfs)
- 깊이 우선 탐색(dfs)
- 데이크스트라
- 플로이드-워셜
- 비트마스킹
- 분리 집합(유니온 파인드)
퀴즈를 제공할 때 유저가 헷갈릴만한 태그 그룹을 보기로 제시하기 위해 태그간 유사성을 판별하였다.
아래 그림은 문제별 태그 matrix를 통해 GramMatrix를 구한 것이다.

위 matrix 태그와 태그의 교집합 개수를 표현하므로는Jaccard방식을 써서 유사성을 판단하면

위와 같은 결과가 나온다.
각 결과를 자기 자신을 제외한 내림차순으로 정리하면 다음과 같다.
|
'그리디 알고리즘': ['다이나믹 프로그래밍', '브루트포스 알고리즘', '이분 탐색', '깊이 우선 탐색'] |
위 결과를 참고하여 어떤 태그가 서로 관련이 있는지 파악하였고 총 3개의 그룹으로 나누었다.
그룹 A : [그리디 알고리즘, 다이나믹 프로그래밍, 브루트포스 알고리즘, 이분 탐색]
그룹 B : [너비 우선 탐색, 깊이 우선 탐색, 브루트포스 알고리즘, 다이나믹 프로그래밍]
그룹 C : [다익스트라, 플루이드 워셜, 비트마스킹, 유니온 파인드]
그룹별 포함된 태그의 개수는 4개로 사용자에게 4지선다형 퀴즈를 제공한다.
JWT 사용자 인증
백엔드 WAS(Web Application Server)에서 사용하는 인증 방법중, 널리 사용되는 2개의 방법으로 Session과 JWT가 있다.

Session방식은 인증 정보를 서버가 가지고 있다(서버는 Stateful)
이 방식은 API 방식으로 BACK과 FRONT가 통신하는 본 프로젝트에는 다소 어울리지 않는다.

JWT방식은 인증 정보를 유저가 가지고있다(서버는 Stateless)
본 프로젝트는 이 방식을 채용하여 유저 인증을 진행하기로 결정하였다.
유저가 로그인 정보를 JSON형식으로 HTTP BODY에 담아 서버에 전달하면, 서버는 토큰을 발행해준다.

유저는 이 토큰을 보관한다. 백서버에 요청할때, 이 토큰을 헤더에 포함시켜 요청한다.
백서버는 토큰을 파싱하여 인증을 진행한다.

토큰을 파싱하면, JWT의 HEADER, PAYLOAD, SIGNATURE. 3가지 타입의 정보를 얻을 수 있다.
HEADER에는 암호화에 사용된 타입, 기법등이 포함된다.
PAYLOAD에는 토큰 발행자가 포함시킨 개인정보가 포함된다. 본 프로젝트에는 loginId와 백에서 사용하는 memberId가 포함된다.
SIGNATURE에는 앞서나온 HEADER와 PAYLOAD. 그리고 토큰발행자의 비밀키까지 3가지를 조합하여 생성된 SIGNATURE key값이 온다. 토큰 인증자는 이 부분을 자신이 발행할때 사용한 비밀키를 이용해 암호를 VERIFY한다.
다음은 VERIFY에 실패했을 경우다. 비밀키에 토큰발행시 사용하지 않는 임의의 키를 넣었다.

다음은 VERIFY에 성공했을 경우다. 비밀키에 토큰발행시 사용한 키를 넣었다.

본 프로젝트에서는 상기한 과정을 통해 사용자를 인증하도록 구성하였다.
인증이 완료되면, 백엔드 서버는 payload에 포함된 memberId를 이용해 business 로직을 수행한다.
백준 문제 크롤링 로직
상기한 10개의 태그를 포함한 모든 백준 문제를 크롤링한다.
태그별 문제 리스트는 다음과 같은 url구조를 갖는다.
https://www.acmicpc.net/problemset?sort=ac_desc&algo={algoCode}&algo_if=and&page={page}algoCode=11page=2
다음은, 위와 같은 URL 주소로 접속했을때의 화면이다.

크롤링할 10개의 태그의 algoCode값은 다음과 같다.
- DP("다이나믹 프로그래밍", 25)
- DFS("깊이 우선 탐색", 127)
- BFS("너비 우선 탐색", 126)
- BRUTE_FORCE("브루트포스 알고리즘", 125)
- GREEDY("그리디 알고리즘", 33)
- BINARY_SEARCH("이분 탐색", 12)
- BIT_MASKING("비트마스킹", 14)
- DIJKSTRA("데이크스트라", 22)
- FLOYD_WARSHALL("플로이드-워셜", 31)
- UNION_FIND("분리 집합", 81)
- DP("다이나믹 프로그래밍", 25)
상기한 url에서, {algoCode}값을 바꿔가며 태그별 문제 리스트에 접근할 수 있고. {page}값을 바꿔가며 첫번째 page부터 마지막 page까지 순회할 수 있다.
각 page에 있는 문제에 접근하여 문제 컨텐츠를 크롤링 해온다. 문제를 크롤링 할때, jsoup프레임워크를 이용해 정적 html을 적절히 파싱한다. 다음은 1000번 문제를 접근했을 때 볼 수 있는 화면이다.

이 화면에서 다음과 같은 항목을 크롤링한다. 각 항목을 화살표 우측의 java 변수값으로 변환한다.
- 시간제한 -> timeLimit
- 메모리 제한 -> memoyLimit
- 문제 -> problemBody
- 입력 -> problemInput
- 출력 -> problemOutput
- 예제입력 -> sampleInput
- 예제출력 -> sampleOutput
위 화면에는 문제의 태그분류(=알고리즘분류)가 빠져있는데, 이는 백준의 태그분류는 로그인 했을 경우만 접근할 수 있기 때문이다. 즉 비로그인 상태에서는 다음과 같은 항목이 나타나지 않는다.

태그분류를 보기위해서 로그인한뒤, 동적 html을 파싱하는 코드를 짤 수 도 있으나. 정적 파싱에 비해 고려해야할 사항도 많고 성능도 떨어진다. 여기서는, 알고리즘 분류를 얻기 위해 solvedac API라는 대안이 있으니. 이를 사용하기로 한다.
solvedac는 백준에 있는 문제들의 난이도를 유저들이 매겨보는 사이트이다. 즉, 알고리즘 문제들의 난이도를 집단지성을 이용해 결정해보자는 취지의 서비스이다. solvedac에선 난이도를 포함한 문제의 메타z이터를 API형태로 제공하는데, 이 API를 통해 로그인해야만 얻을 수 있던 태그분류(=알고리즘분류)데이터를 얻을 수 있다.
다음과 같이 solvedac api서버에 문제를 요청한다.
curl--request GET \ --url https://solved.ac/api/v3/problem/show \ --header 'Accept: application/json'
이에대한 HHTP요청에 대한 응답으로, 이와 같은 json을 얻을 수 있다.
{
"problemId": 13705,
"titleKo": "Ax+Bsin(x)=C",
"titles": [
{
"language": "ko",
"languageDisplayName": "ko",
"title": "Ax+Bsin(x)=C",
"isOriginal": true
}
],
...(생략)
"tags": [
{
"key": "arbitrary_precision",
"isMeta": false,
"bojTagId": 117,
"problemCount": 113,
"displayNames": [
{
"language": "ko",
"name": "임의 정밀도 / 큰 수 연산",
"short": "임의 정밀도 / 큰 수 연산"
}
]
...(생략)
}
json의 tags를 이용해 원하는 문제 번호의 태그분류를 얻을 수 있다.
추가로, titles의 language를 보면 "ko"라고 되어있는데. 문제가 한국어로 서술되어 있다는 뜻이다.
즉 문제의 서술 언어를 확인할 수 있는데. 이 정보를 이용해 유저들에게 한국어로 된 문제만 제공한다.
jsoup을 이용해 정적 데이터를 크롤링 했고. API호출을 통해 태그분류와 문제서술 언어정보를 얻었다.
다음과 같은 java코드를 작성해, 데이터가 존재하지 않을경우 skip하도록 한다.
if (timeLimit.equals(0) //시간제한이 존재하지 않을경우 기본값 0을 갖도록 전처리되어있음 || memoryLimit.equals(0) //메모리제한이 존재하지 않을경우 기본값 0을 갖도록 전처리되어있음 || problemBody.isBlank() || problemInput.isBlank() || problemOutput.isBlank() || sampleInput.isBlank() || sampleOutput.isBlank()) return;
또한, 다음과 같은 java 코드를 작성해 언어가 한국어가 아니거나 태그분류가 없을 경우 skip한다.
if (solvedAcProblemDto.getTitles().stream().noneMatch(e -> e.getLanguage().equals("ko"))) return; if (solvedAcProblemDto.getTags().isEmpty()) return;
필터링을 통과한 데이터는 하나의 객체로 만들어 DB에 저장하는 것으로 크롤링을 끝마친다.
상기한 일련의 과정들을 코드로 구현할때, Java의 parallel stream 규격에 맞추어 구현하였다. 일반 Java stream 코드일 때는 싱글스레드로 크롤링 해왔지만 ava parallel stream 코드일때는 멀티스레드로 크롤링 해온다.
동일하드웨어 환경에서 멀티스레드와 싱글스레드 크롤링 속도를 비교해보았다.
(cpu:i5-6600 4core 4thread gpu:gtx960 ram:16gm)
멀티스레드 크롤링 결과이다. 307.802826100초 걸렸다.

싱글스레드 크롤링 결과이다. 742.580477200초 걸렸다.

멀티스레드 크롤링 시간과 싱글스레드 크롤링 시간이 약 2배정도 되는걸 확인할 수 있다.
Parallet stream은 자동으로 모든 thread에 적절히 작업을 분배해 나눠주므로 hread수가 늘어난다면 성능차이는 더욱 커질거라 예상된다.
Quiz 생성 로직
백준의 태그들과 상기한 3개의 태그그룹에 속한 태그들의 교집합 갯수가 1개일 경우만 Quiz를 생성한다.
그룹에 포함된 4개의 태그를 4지선다로 사용하고. 교집합 1개를 정답 태그로 한다.
ERD

위의 ERD와 같이 DB를 구성하였다.
DB에 직접 SQL문을 질의하지 않았고, Java ORM기술인 JPA를 사용하여 CRUD를 수행하였다.
흐름도

ELO 시스템
기존 ELO 시스템은 다음과 같다.

다음은 기존 ELO시스템을 설명하는 도식이다.

ELO경쟁에 참여한 모두가 동등하다.
User의 전체 승률이 50%이다.
user ELO 평균은 초기값 1200에 수렴한다.
기존 ELO를 본 프로젝트에 적용할 경우, user와 quiz가 동등하지 않음에 따라 문제가 발생한다.
다음 도식에 표현하였다.

ELO 경쟁에 참여한 모두가 동등하지 않다.
만약, user승률 평균은 70%, quiz승률 평균은 30%이라 하면 quiz ELO 평균값은 지속적으로 감소하게 되고, user ELO 평균값은 지속적으로 증가하게 된다.
이 경우, 다음과 같은 문제가 발생한다.

문제점 : 신규 유저는 quiz중에 가장 어려운 문제를 첫 문제로 조우하게 된다.
이를 해결하기 위해 기존 ELO를 변형하여 다음과 같이 적용한다.

기존 K값은 사용자가 정한 임의의 고정값이었는데,
본 프로젝트에서는 quiz와 user사이의 정답률에 의해 동적으로 변경되는 값으로 사용하도록 변경한다.


변경된 ELO시스템에서는 승률평균은 50%에 수렴하지 않을지더라도, 각 그룹의 ELO평균은 1200으로 수렴하게 된다. 이에 따라 quiz ELO 평균값은 1200으로 수렴할 것이라 기대되고, user ELO 평균값은 1200으로 수렴할 것이라 기대된다.
유저 취약 TAG 기반 Problem 추천
위에서 상기한 QUIZ의 정답률을 기반으로 해당 유저의 TAG별 정답률을 기록하게 된다.
이 정답률이 낮을 수록 해당 TAG에 대한 PRBLEM 추천 확률이 정비례로 높아지게 된다.
이런 확률로 선택된 TAG는 AUTO_ENCODER_CONST 모델을 거쳐 사용자에게 PROBLEM을 추천하게 된다.
상세설계 내용
◇ AI
- Amazon EC2 환경에서 서버 배포
- 모델 성능 비교 및 도메인을 고려하여 모델 선정
- AUTO_ENCODER, EASE 모델 업로드 및 모델 적용을 통한 문제 추천
◇ Back-end
- Amazon EC2 환경에서 서버 배포
- Amazon RDS로 Maria DB 인스턴스 관리
- Front-end에게 필요한 데이터 전달
- - Amazon S3를 활용하여 이미지 리소스 전달
- - Swagger를 활용하여 API 명세서 공유
◇ Front-end
- Amazon EC2 환경에서 서버 배포
- Back-end로부터 전달받은 데이터를 CLIENT에게 전달하며 구현한 화면에 포함시킴
◇ Infra
- AI, Back-end, Front-end 서버를 Docker Compose를 활용하여 배포
- GitHub Actions를 활용하여 CI/CD 적용
결과 및 평가
완료 작품의 소개
프로토타입 사진 혹은 작동 장면
◇ 메인 페이지
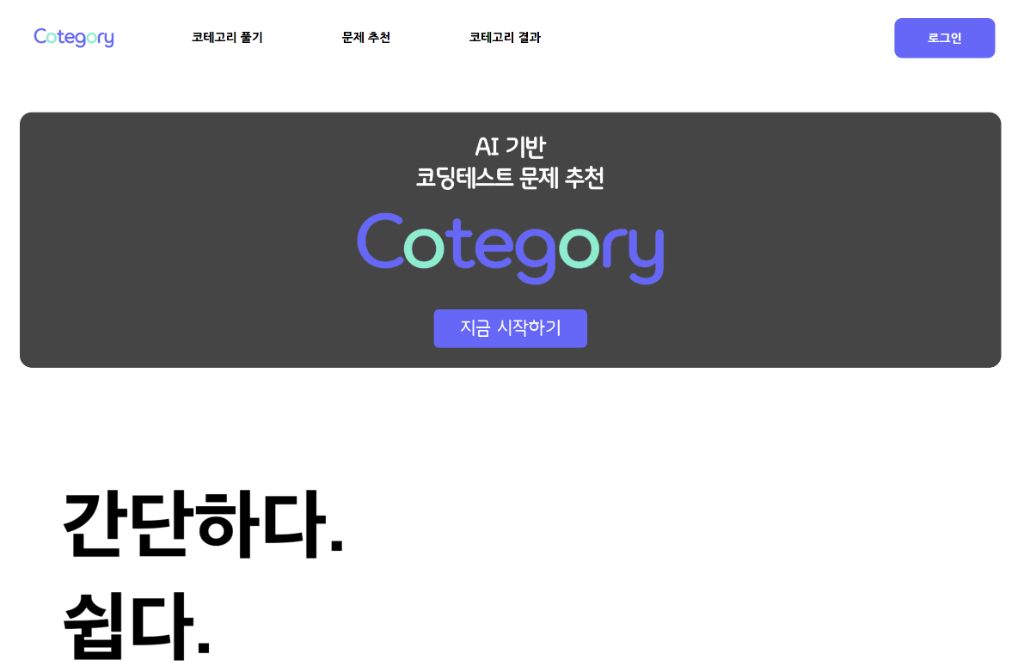
- 헤더에서 코테고리 풀기, 문제 추천, 코테고리 결과, 로그인(프로필) 페이지로 이동
- 서비스에 대한 간단한 설명을 메인 배너 하단에 배치

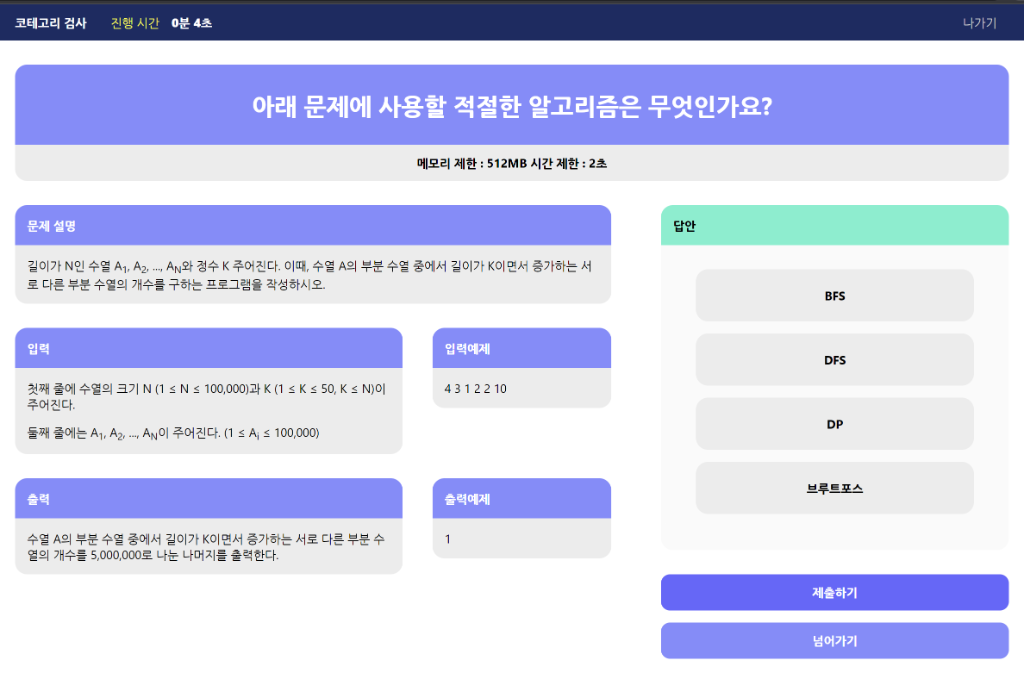
◇ 퀴즈 풀이 페이지
- 답안 제출전
- 답안 제출후
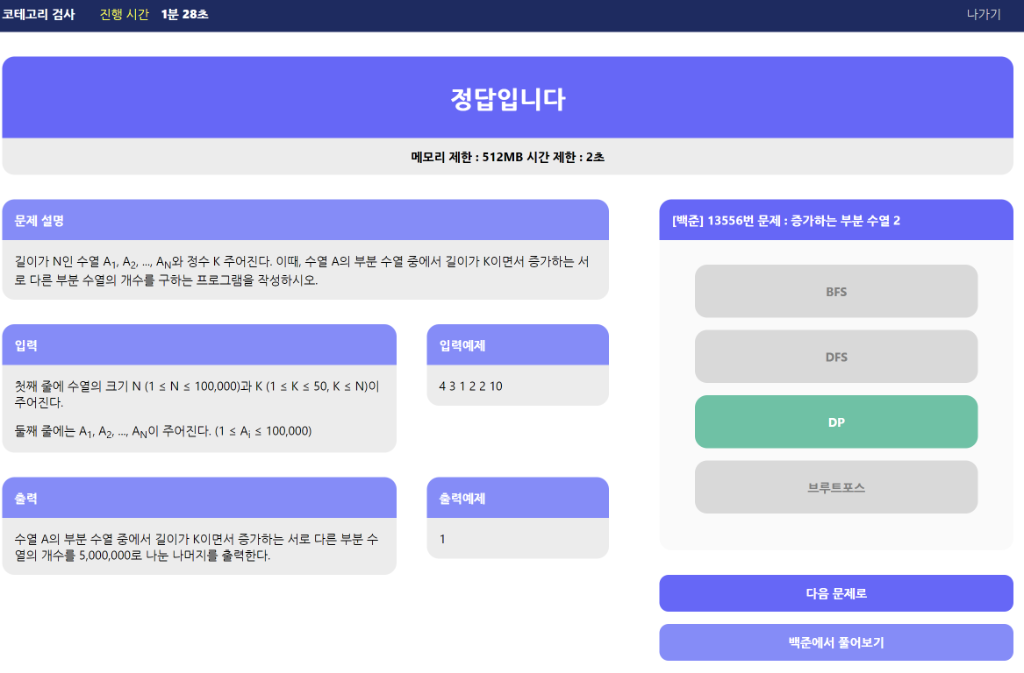
- 문제 설명, 입력, 출력, 입력예제, 출력예제 및 메모리 제한, 시간 제한 정보로 코딩테스트 문제에 대한 유형 분류 퀴즈를 제공
- 상단에 진행 시간을 배치하여 얼마나 이른 시간 내에 유형을 분류할 수 있는지에 대한 정보 제공
- 문제 별 4지선다를 제공하여 답안을 제출하도록 함
- 제출 후 정/오답 결과를 제공하고, 실제 문제 사이트에서 풀이할 수 있도록 링크를 제공


◇ 코딩테스트 문제 추천 페이지
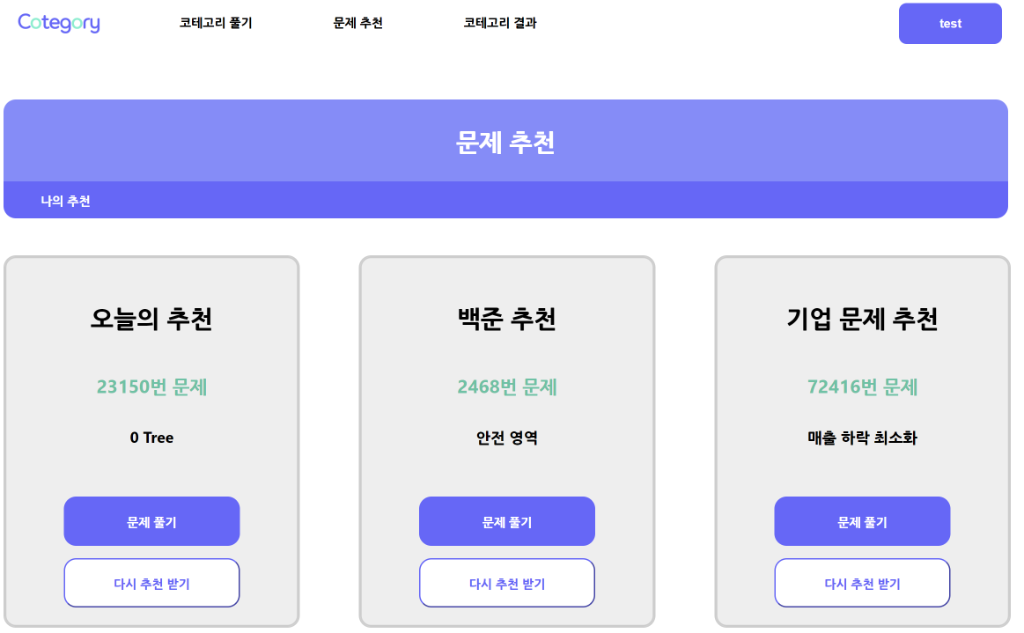
- 사용자 백준 풀이 정보 및 코테고리 퀴즈 결과를 기반으로한 코딩테스트 문제를 추천
- 이 외에도 오늘의 추천, 실제 기업 기출 문제 추천을 제공

◇ 퀴즈 풀이 결과 페이지
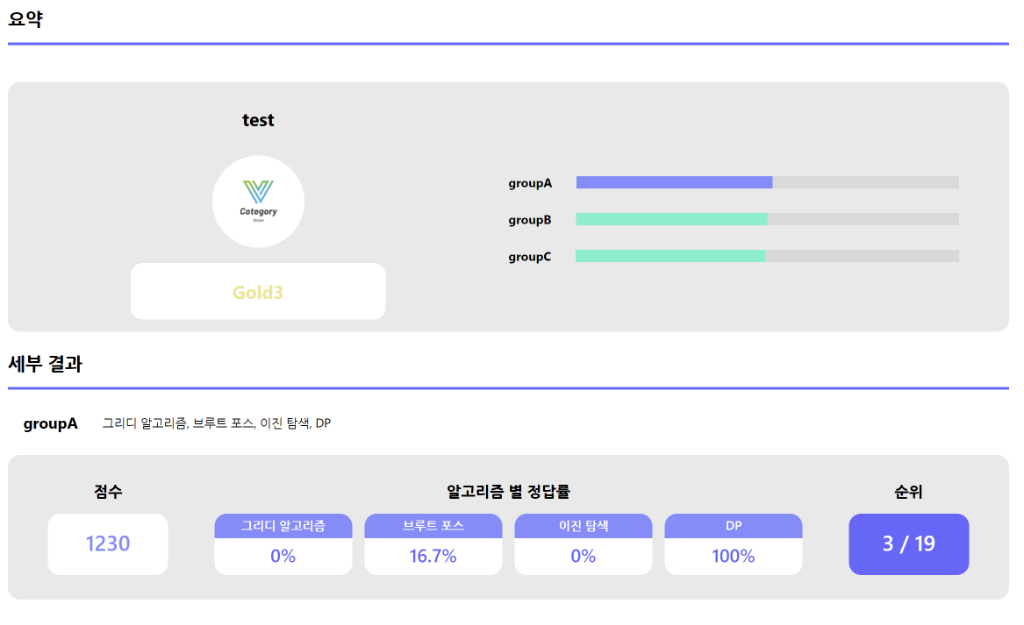
- 사용자가 푼 퀴즈를 바탕으로 등급, mmr 점수, 알고리즘 별 정답률, 순위를 제공

포스터
포스터 제작한 바 없음
관련사업비 내역서
| 항 목 (품명, 규격) |
수 량 | 단 가 | 금 액 | 비 고 | |||
|---|---|---|---|---|---|---|---|
| 계 | 현금 | 비고 | |||||
| 직 접 개 발 비 |
AWS EC2 Server 사용비 | 1 | KRW 205,819.37 | 1 | KRW 205,819.37 | |
|
| |
|
|
|
|
|
| |
| |
|
|
|
|
|
| |
| |
|
|
|
|
|
| |
| |
|
|
|
|
|
| |
| |
|
|
|
|
|
| |
| |
|
|
|
|
|
| |
| 합 계 | 1 | KRW 205,819.37 | 1 | KRW 205,819.37 | |
| |
완료작품의 평가
| 평 가 항 목 | 평가방법 | 적용기준 | 개발목표치 | 비중(%) | 평가결과 |
|---|---|---|---|---|---|
| 1. 사용자 문제 풀이 시간 향상 척도 | DB에 문제푸는데 걸린 시간을 기록한다. 이를 이용해 문제 푸는 시간 향상 정도를 파악한다. |
A : 푸는 시간이 향상된 유저가 전체 유저의 70% 이상 B : 향상된 유저가 50% 이상 C : 그 외 |
적용기준 A에 해당하는 효과 구현 | 30% | A |
| 2. 사용자 퀴즈 정확도 향상 척도 | DB에 퀴즈 정확도를 기록한다. 이를 이용해 문제 풀이 정확도 향상 정도를 파악한다. |
A : 정확도가 향상된 유저가 전체 유저의 70% 이상 B : 향상된 유저가 50% 이상 C : 그 외 |
적용기준 A에 해당하는 효과 구현 | 30% | A |
| 3. 서비스 유용성 | 사용자에게 설문조사를 실시한다. | A : 전체 설문 항목의 80%이상에서 긍정적 답변을 얻는다 B : 그외 |
적용기준 A에 해당하는 효과 구현 | 40% | A |
향후계획
◇ 어드민 페이지 화면 구현
- 퀴즈 문제 검수
- 퀴즈 문제 등록
- 사용자 신고/차단/강제 탈퇴
특허 출원 내용
특허 출허한 바 없음